#numpy playlist
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Text
Machine Learning Fundamentals
Machine learning (ML) is the heartbeat of artificial intelligence, enabling computers to learn patterns from data and make decisions autonomously — think of Spotify curating playlists based on your listening habits or e-commerce platforms predicting your next purchase. It’s a versatile skill applicable across industries, from finance to entertainment, and its importance is only growing as data becomes the new oil. Today, ML is trending toward integration with edge computing, allowing devices like wearables to process data locally, while innovations like federated learning promise privacy-preserving AI training. The future could see ML democratized further through automated machine learning (AutoML), enabling even non-experts to build models. The Certified Machine Learning Engineer program is your gateway into this field, offering hands-on training in supervised and unsupervised learning, algorithms like random forests and gradient boosting, and practical deployment using tools like TensorFlow. This certification validates your ability to craft ML solutions that solve real-world problems, making you a sought-after professional.
To round out your ML expertise, consider the Data Science with Python Certification, which dives into data preprocessing, exploratory analysis, and advanced ML with Python’s rich ecosystem — think Pandas, NumPy, and Scikit-learn. The AI Algorithms Specialist Certification offers a deeper dive into the math behind ML, such as linear algebra and optimization, perfect for those who love theory. For a practical twist, the ML Ops Engineer Certification teaches you to streamline ML workflows, from development to production. Together, these certifications build a robust ML portfolio. Elevate your skills further with AI CERTs��, which provides cutting-edge training in AutoML, AI ethics, and scalable ML deployment, ensuring you’re ready for both current demands and future shifts. With this combination, you’ll be a powerhouse in ML, ready to innovate and lead.
0 notes
Text
New Study Reveals 70% of Python Developers Use Virtual Environments for Efficient Coding. Dive into the Data and Enhance Your Python Skills Today!
Real Python Blog
Unlocking the Power of Python: Key Facts, Hard Information, and Concrete Data
Welcome to our blog, where we delve into the fascinating world of Python programming. In this article, we will provide you with an in-depth exploration of key facts, hard information, and concrete data that highlight the true power and versatility of Python. Brace yourself for a mind-blowing journey filled with numerical insights, objective analysis, and informative content that will leave you astounded.
1. Python's Explosive Growth in the Tech Industry
Let's start by examining the impressive growth of Python in the tech industry. According to the latest statistics, Python is the second most popular programming language globally, with a staggering 8.2 million developers actively using it. This number represents a remarkable 28% increase from the previous year, indicating the immense demand for Python in various sectors.
2. Real-World Applications of Python
Python's versatility extends far beyond its popularity in terms of sheer numbers. The language finds real-world applications in a wide range of fields, including:
Data Science: Python's rich ecosystem of libraries such as NumPy, Pandas, and Matplotlib makes it the go-to language for data analysis and visualization.
Web Development: Python frameworks like Django and Flask enable developers to build robust and scalable web applications with ease.
Artificial Intelligence and Machine Learning: Python's simplicity and extensive libraries like Tensorflow and Keras have propelled its dominance in AI and ML research.
Scripting and Automation: Python's concise syntax and powerful libraries make it ideal for automating repetitive tasks and writing efficient scripts.
3. Growth in Python-Based Technologies
Python's impact extends beyond the core language itself. Let's dive into some key Python-based technologies and their impressive growth:
3.1. Flask Framework
Flask, a lightweight and flexible Python web framework, has experienced a remarkable 50% increase in adoption rates over the past year. Its simplicity and extensibility make it a popular choice among developers for building scalable web applications.
3.2. Pandas Library
Pandas, a powerful data manipulation and analysis library, has gained significant traction in the past few years. With a remarkable 45% increase in usage, Pandas has become an indispensable tool for data scientists and analysts worldwide.
4. Python's Influence on Major Companies
Python has emerged as a language of choice for major companies across various industries. Some notable examples include:
Google: Python serves as a backbone for numerous Google services, including YouTube, Google Search, and Google App Engine.
Netflix: Python's simplicity and efficiency have made it a preferred language for Netflix's extensive data processing and recommendation systems.
Instagram: This popular social media platform utilizes Python for its backend infrastructure, supporting over 1 billion users worldwide.
Spotify: Python plays a crucial role in Spotify's music recommendation algorithms, providing users with personalized playlists and discoverability.
5. The Inherent Advantages of Python
Python offers a myriad of advantages that contribute to its popularity and continued growth:
5.1. Readability and Simplicity
Python's clean and readable syntax allows developers to express complex ideas with minimal code, fostering efficient collaboration and reducing development time.
5.2. Large and Active Community
With millions of dedicated developers worldwide, Python boasts one of the largest and most vibrant communities in the programming world. This thriving community ensures that Python remains up-to-date, constantly evolving, and supported by a vast array of libraries and frameworks.
5.3. Cross-Platform Compatibility
Python effortlessly runs on various operating systems, including Windows, macOS, and Linux. This cross-platform compatibility makes it an ideal choice for developing applications that can seamlessly transition between different environments.
5.4. Extensive Library Ecosystem
Python's extensive library ecosystem empowers developers with a vast array of pre-existing code and functionalities. This eliminates the need to reinvent the wheel, allowing developers to focus on building innovative solutions without getting bogged down in repetitive tasks.
6. RoamNook: Fueling Digital Growth
Now that you've explored the incredible world of Python, it's time to introduce you to RoamNook—an innovative technology company dedicated to fueling digital growth. With expertise in IT consultation, custom software development, and digital marketing, RoamNook stands at the forefront of driving technology advancements.
By harnessing the power of Python, RoamNook delivers cutting-edge solutions that empower businesses to thrive in the digital landscape. Whether it's developing scalable web applications, designing data-driven marketing strategies, or providing expert consultation, RoamNook has the knowledge and passion to help your business succeed.
So, why wait? Give your business the competitive edge it deserves. Reach out to RoamNook today and embark on a transformative journey towards digital growth.
Conclusion: Reflecting on the Power of Python
As we conclude this captivating exploration of Python's power, it's essential to reflect on the impact this language has on our lives and the tech industry as a whole. From its explosive growth to its unparalleled versatility, Python has solidified its position as a dominant force in programming.
By embracing Python, individuals and organizations can unlock their full potential, harnessing this language's simplicity, efficiency, and endless possibilities. So, are you ready to embark on a Pythonic journey? Are you prepared to discover the vast horizons that Python has to offer?
We invite you to join the ever-expanding Python community, leverage the power of RoamNook's expertise, and embark on a transformative digital journey. Start harnessing the power of Python today and witness firsthand the wonders it can bring to your life and career.
Related Content:
RoamNook - Fueling digital growth through innovative technology solutions
Python.org - The official website of the Python programming language
Source: https://realpython.com/python-virtual-environments-a-primer/&sa=U&ved=2ahUKEwie3put9quGAxXWFlkFHSgsAb8QFnoECAoQAg&usg=AOvVaw1uX13K4qS_KxVwz1OF1FRA
0 notes
Text
youtube
Python Numpy Tutorials
#numpy tutorials#numpy for beginners#numpy arrays#what is array in numpy#numpy full array#how to create numpy full array#what is numpy full array#how to use numpy full array#uses of numpy full array#how to define the shape of numpy array#python for beginners#python full course#numpy full course#numpy python playlist#numpy playlist#complete python numpy tutorials#numpy full array function#python array#python numpy library#how to create arrays in python numpy#Youtube
0 notes
Link
#python #NumPy is a goto library for any numerical computation including data science. Here is how you can learn NumPy - 1 Function at a time
2 notes
·
View notes
Text
Best python ide for gui

#BEST PYTHON IDE FOR GUI CODE#
PyQt applications run much better in practice from a user perspective than something like Electron. OTOH, with something like Electron, you are going through a browsery DOM with a bunch more layers of abstraction between you and the meat of what's actually happening.
#BEST PYTHON IDE FOR GUI CODE#
If you are doing normal GUI development, you are only using Python to orchestrate objects that are implemented in C++, so the actual implementation of the widgets is all native code that runs great. (But both are terrible languages for that.) If you are doing hard core number crunching or the like, Javascript is much faster than pure Python. > I bet you money electron is faster than python. I have used that combination on several commercial ventures in the past. Generally speaking, a cross-platform toolkit and a cross-platform language can get you into most places, and both Qt and Python fit that bill. What do you mean by "fast and efficient"? Python and Qt can handle user interactions in real-time, even with hundreds of controls. So it depends on what you want to use it for. Android and iOS each have their own standard languages and frameworks. If you are having to learn a toolkit either way, it's worth considering.ĭepending on your experience and intended platforms, you may prefer other language/framework combinations. I don't know as much about it, but I do know that it's quite capable. Not quite as fancy, but quite capable.Ī more recent toolkit is kivy. There's also wxWidgets, which is fine too. PySide provides convenient, reliable interfaces to Qt within Python.Qt is very powerful with basically everything you could ever think of in a toolkit (and a bunch more stuff you'll never use).My employer uses Qt through PySide and it's great. Introduction to Programming with Python (from Microsoft Virtual Academy)./r/git and /r/mercurial - don't forget to put your code in a repo!./r/pyladies (women developers who love python)./r/coolgithubprojects (filtered on Python projects)./r/pystats (python in statistical analysis and machine learning)./r/inventwithpython (for the books written by /u/AlSweigart)./r/pygame (a set of modules designed for writing games)./r/django (web framework for perfectionists with deadlines)./r/pythoncoding (strict moderation policy for 'programming only' articles).NumPy & SciPy (Scientific computing) & Pandas.Transcrypt (Hi res SVG using Python 3.6 and turtle module).Brython (Python 3 implementation for client-side web programming).PythonAnywhere (basic accounts are free).(Evolved from the language-agnostic parts of IPython, Python 3).The Python Challenge (solve each level through programming).Problem Solving with Algorithms and Data Structures.Udemy Tech Youtube channel - Python playlist Invent Your Own Computer Games with Pythonįive life jackets to throw to the new coder (things to do after getting a handle on python) Please use the flair selector to choose your topic.Īdd 4 extra spaces before each line of code def fibonacci(): Reddit filters them out, so your post or comment will be lost. If you are about to ask a "how do I do this in python" question, please try r/learnpython, the Python discord, or the #python IRC channel on Libera.chat. 12pm UTC – 2pm UTC: Bringing ML Models into Production Bootcamp News about the dynamic, interpreted, interactive, object-oriented, extensible programming language Python Current Events
0 notes
Text
Randomly ketemu profesor dari India di linkedin, terus kan gue dm tuh si profesor, karena kagak paham dia profesor, gue panggil dia pake nama langsung awalnya haha. Abis sapa sapaan di linkedin, dia nawarin internship. Gue isi dah tuh formnya. Internshipnya ini agendanya ngerjain tugas daily sama weekly tentang python gitu. Abis gue daptar, gue diemail kalo gue diterima.
Terus dia ngasih tau metode intern nya kaya gimana, jadi dia udah provide video gitu di yutub ada sebuah playlist machine learning berisi 79 video soal numpy, pandas, scikit, gitu2. Dia gak provide link colab ataupun github buat sintax yang di yutub itu, jadi tugas gue tiap hari adalah menyalin sintax nya ke python dan bikin catatan terus di email tiap hari ke profesornya. As simple as that, tapi jujurly metode ini keren banget menurut gue sebagai seseorang yang males belajar kalo ga ada trigger. Ini membantu banget buat gue bisa konsisten belajar tiap hari gitu lho huhu. Baiknya, si profesor ini ngasih ini cuma2, terus orangnya responsif, apresiatif, duh bae banget dah pokoknya. Aku padamu negeri prindapan. Dia tiap abis gue ngumpulin tugas nge chat gue.
“you’re doing a good work dwi, keep it up” gitu
trus dia juga bilang gini
“Free education is abundant, all over the internet. It’s the desire to learn that scarce”
Mungkin berangkat dari situ lah dia membikin internship ini, karena kelangkaan minat belajar. Jadi dia ngga cuma bikin konten di yutub doang, karena dia sadar udah banyak yang bikin.
Jujurly metode belajar berbayar pun ga mempan di gue, meski udah beli di udemy, ato mungkin bootcamp sekalipun, kalo metodenya kurang pas gue akan tetep males. Gue butuh dipaksa untuk ngerjain tiap hari, dan gue seneng banget ketemu nih prof nirmal negeri prindapan.
1 note
·
View note
Text
Machine Learning
https://youtube.com/playlist?list=PLCmAM0wpuQ4910msQ5Bs8txh2LqvWLV4R
Python Tkinter Library
https://youtube.com/playlist?list=PLCmAM0wpuQ49Mgfe1wz8tCQRh3NMWtHhq
Java Full course
https://youtube.com/playlist?list=PLCmAM0wpuQ48HV8ph_oKf1haNpntsFGAr
Pandas Full cours
https://youtube.com/playlist?list=PLCmAM0wpuQ4-vdg-JtGgRm0rgMC1QnvH8
WordPress full course
https://youtube.com/playlist?list=PLCmAM0wpuQ49HpucvtT7dMe7L2X2BBsAO
Numpy
https://youtube.com/playlist?list=PLCmAM0wpuQ4_82zMt05FNLMrWaGLLP-4H
String function in c program
https://youtube.com/playlist?list=PLCmAM0wpuQ4-4iQsIovYPxY-lDc714aln
Matplotlib data visualization
https://youtube.com/playlist?list=PLCmAM0wpuQ49cqfUZRBP-nOQBeCqLKxZ5
Python
https://youtube.com/playlist?list=PLCmAM0wpuQ484UV_lo5l_F0IZLdk1H4z4
Ethical hacking
https://youtube.com/playlist?list=PLCmAM0wpuQ48Oet9rkIItDkDjhzpq8fLD
Subscribe my youtube channel and press bell icon to get instant notification when we will upload video
#programming #SmartCoding #machinelearning #bestprogramever #video
0 notes
Text
My Programming Journey: Understanding Music Genres with Machine Learning
Artificial Intelligence is used everyday, by regular people and businesses, creating such a positive impact in all kinds of industries and fields that it makes me think that AI is only here to stay and grow, and help society grow with it. AI has evolved considerably in the last decade, currently being able to do things that seem taken out of a Sci-Fi movie, like driving cars, recognizing faces and words (written and spoken), and music genres.
While Music is definitely not the most profitable application of Machine Learning, it has benefited tremendously from Deep Learning and other ML applications. The potential AI possess in the music industry includes automating services and discovering insights and patterns to classify and/or recommend music.
We can be witnesses to this potential when we go to our preferred music streaming service (such as Spotify or Apple Music) and, based on the songs we listen to or the ones we’ve previously saved, we are given playlists of similar songs that we might also like.
Machine Learning’s ability of recognition isn’t just limited to faces or words, but it can also recognize instruments used in music. Music source separation is also a thing, where a song is taken and its original signals are separated from a mixture audio signal. We can also call this Feature Extraction and it is popularly used nowadays to aid throughout the cycle of music from composition and recording to production. All of this is doable thanks to a subfield of Music Machine Learning: Music Information Retrieval (MIR). MIR is needed for almost all applications related to Music Machine Learning. We’ll dive a bit deeper on this subfield.
Music Information Retrieval
Music Information Retrieval (MIR) is an interdisciplinary field of Computer Science, Musicology, Statistics, Signal Processing, among others; the information within music is not as simple as it looks like. MIR is used to categorize, manipulate and even create music. This is done by audio analysis, which includes pitch detection, instrument identification and extraction of harmonic, rhythmic and/or melodic information. Plain information can be easily comprehended (such as tempo (beats per minute), melody, timbre, etc.) and easily calculated through different genres. However, many music concepts considered by humans can’t be perfectly modeled to this day, given there are many factors outside music that play a role in its perception.
Getting Started
I wanted to try something more of a challenge for this post, so I am attempting to Visualize and Classify audio data using the famous GTZAN Dataset to perform an in depth analysis of sound and understand what features we can visualize/extract from this kind of data. This dataset consists of: · A collection of 10 genres with 100 audio (WAV) files each, each having a length of 30 seconds. This collection is stored in a folder called “genres_original”. · A visual representation for each audio file stored in a folder called “images_original”. The audio files were converted to Mel Spectrograms (later explained) to make them able to be classified through neural networks, which take in image representation. · 2 CVS files that contain features of the audio files. One file has a mean and variance computed over multiple features for each song (full length of 30 seconds). The second CVS file contains the same songs but split before into 3 seconds, multiplying the data times 10. For this project, I am yet again coding in Visual Studio Code. On my last project I used the Command Line from Anaconda (which is basically the same one from Windows with the python environment set up), however, for this project I need to visualize audio data and these representations can’t be done in CLI, so I will be running my code from Jupyter Lab, from Anaconda Navigator. Jupyter Lab is a web-based interactive development environment for Jupyter notebooks (documents that combine live runnable code with narrative text, equations, images and other interactive visualizations). If you haven’t installed Anaconda Navigator already, you can find the installation steps on my previous blog post. I would quickly like to mention that Tumblr has a limit of 10 images per post, and this is a lengthy project so I’ll paste the code here instead of uploading code screenshots, and only post the images of the outputs. The libraries we will be using are:
> pandas: a data analysis and manipulation library.
> numpy: to work with arrays.
> seaborn: to visualize statistical data based on matplolib.
> matplotlib.pyplot: a collection of functions to create static, animated and interactive visualizations.
> Sklearn: provides various tools for model fitting, data preprocessing, model selection and evaluation, among others.
· naive_bayes
· linear_model
· neighbors
· tree
· ensemble
· svm
· neural_network
· metrics
· preprocessing
· decomposition
· model_selection
· feature_selection
> librosa: for music and audio analysis to create MIR systems.
· display
> IPython: interactive Python
· display import Audio
> os: module to provide functions for interacting with the operating system.
> xgboost: gradient boosting library
· XGBClassifier, XGBRFClassifier
· plot_tree, plot_importance
> tensorflow:
· Keras
· Sequential and layers
Exploring Audio Data
Sounds are pressure waves, which can be represented by numbers over a time period. We first need to understand our audio data to see how it looks. Let’s begin with importing the libraries and loading the data:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import sklearn
import librosa
import librosa.display
import IPython.display as ipd
from IPython.display import Audio
import os
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import SGDClassifier, LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.neural_network import MLPClassifier
from xgboost import XGBClassifier, XGBRFClassifier
from xgboost import plot_tree, plot_importance
from sklearn.metrics import confusion_matrix, accuracy_score, roc_auc_score, roc_curve
from sklearn import preprocessing
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import RFE
from tensorflow.keras import Sequential
from tensorflow.keras.layers import *
import warnings
warnings.filterwarnings('ignore')
# Loading the data
general_path = 'C:/Users/807930/Documents/Spring 2021/Emerging Trends in Technology/MusicGenre/input/gtzan-database-music-genre-classification/Data'
Now let’s load one of the files (I chose Hit Me Baby One More Time by Britney Spears):
print(list(os.listdir(f'{general_path}/genres_original/')))
#Importing 1 file to explore how our Audio Data looks.
y, sr = librosa.load(f'{general_path}/genres_original/pop/pop.00019.wav')
#Playing the audio
ipd.display(ipd.Audio(y, rate=sr, autoplay=True))
print('Sound (Sequence of vibrations):', y, '\n')
print('Sound shape:', np.shape(y), '\n')
print('Sample Rate (KHz):', sr, '\n')
# Verify length of the audio
print('Check Length of Audio:', 661794/22050)
We took the song and using the load function from the librosa library, we got an array of the audio time series (sound) and the sample rate of sound. The length of the audio is 30 seconds. Now we can trim our audio to remove the silence between songs and use the librosa.display.waveplot function to plot the audio file into a waveform. > Waveform: The waveform of an audio signal is the shape of its graph as a function of time.
# Trim silence before and after the actual audio
audio_file, _ = librosa.effects.trim(y)
print('Audio File:', audio_file, '\n')
print('Audio File Shape:', np.shape(audio_file))
#Sound Waves 2D Representation
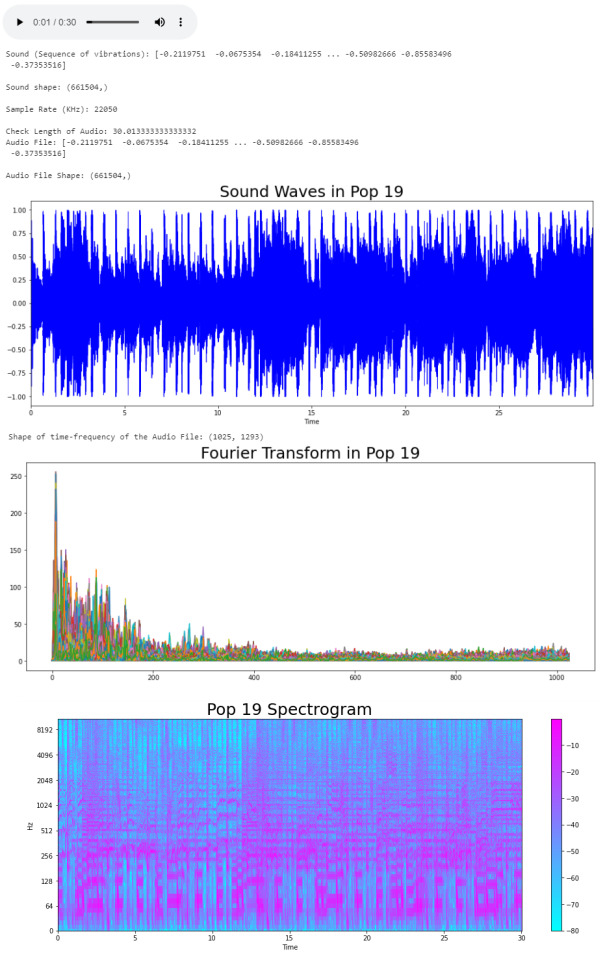
plt.figure(figsize = (16, 6))
librosa.display.waveplot(y = audio_file, sr = sr, color = "b");
plt.title("Sound Waves in Pop 19", fontsize = 25);
After having represented the audio visually, we will plot a Fourier Transform (D) from the frequencies and amplitudes of the audio data. > Fourier Transform: A mathematical function that maps the frequency and phase content of local sections of a signal as it changes over time. This means that it takes a time-based pattern (in this case, a waveform) and retrieves the complex valued function of frequency, as a sine wave. The signal is converted into individual spectral components and provides frequency information about the signal.
#Default Fast Fourier Transforms (FFT)
n_fft = 2048 # window size
hop_length = 512 # number audio of frames between STFT columns
# Short-time Fourier transform (STFT)
D = np.abs(librosa.stft(audio_file, n_fft = n_fft, hop_length = hop_length))
print('Shape of time-frequency of the Audio File:', np.shape(D))
plt.figure(figsize = (16, 6))
plt.plot(D);
plt.title("Fourier Transform in Pop 19", fontsize = 25);
The Fourier Transform only gives us information about the frequency values and now we need a visual representation of the frequencies of the audio signal so we can calculate more audio features for our system. To do this we will plot the previous Fourier Transform (D) into a Spectrogram (DB). > Spectrogram: A visual representation of the spectrum of frequencies of a signal as it varies with time.
DB = librosa.amplitude_to_db(D, ref = np.max)
# Creating the Spectrogram
plt.figure(figsize = (16, 6))
librosa.display.specshow(DB, sr = sr, hop_length = hop_length, x_axis = 'time', y_axis = 'log'
cmap = 'cool')
plt.colorbar();
plt.title("Pop 19 Spectrogram", fontsize = 25);
The output:
Audio Features
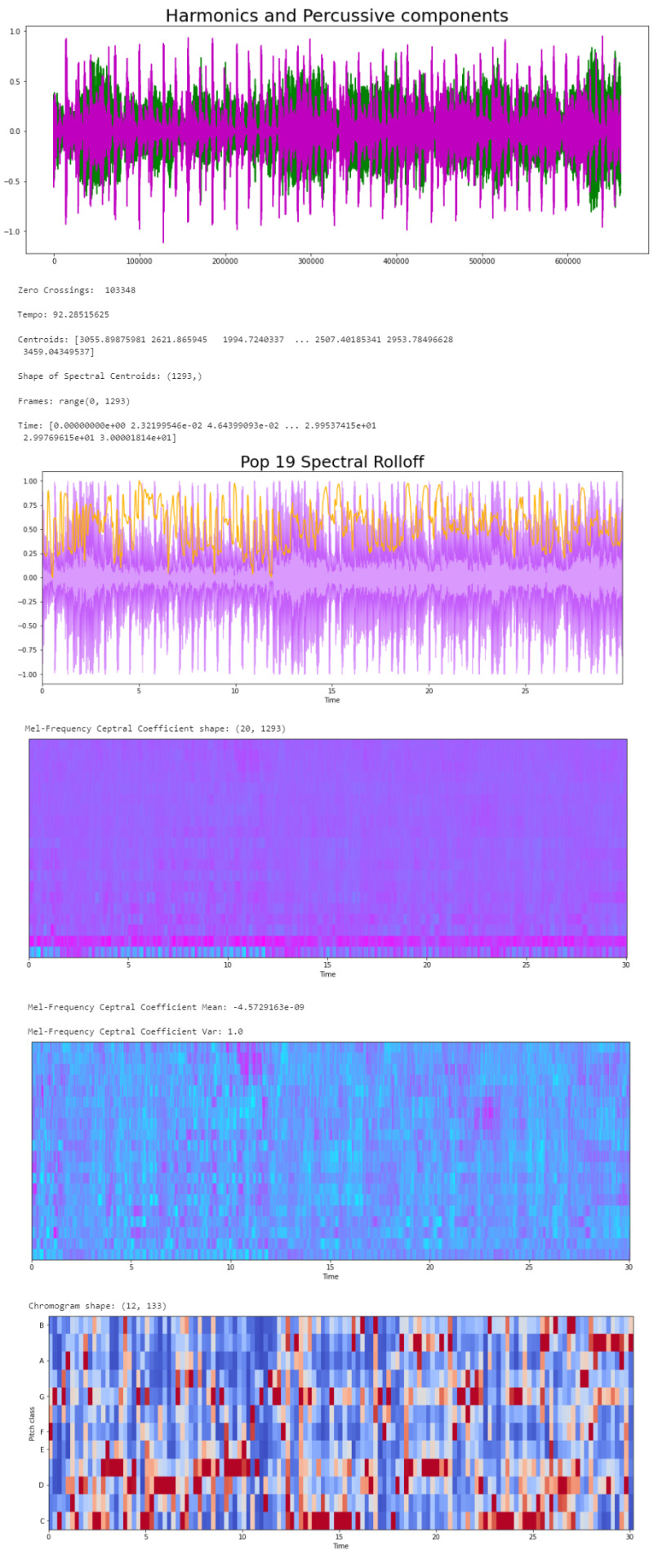
Now that we know what the audio data looks like to python, we can proceed to extract the Audio Features. The features we will need to extract, based on the provided CSV, are: · Harmonics · Percussion · Zero Crossing Rate · Tempo · Spectral Centroid · Spectral Rollof · Mel-Frequency Cepstral Coefficients · Chroma Frequencies Let’s start with the Harmonics and Percussive components:
# Decompose the Harmonics and Percussive components and show Representation
y_harm, y_perc = librosa.effects.hpss(audio_file)
plt.figure(figsize = (16, 6))
plt.plot(y_harm, color = 'g');
plt.plot(y_perc, color = 'm');
plt.title("Harmonics and Percussive components", fontsize = 25);
Using the librosa.effects.hpss function, we are able to separate the harmonics and percussive elements from the audio source and plot it into a visual representation.
Now we can retrieve the Zero Crossing Rate, using the librosa.zero_crossings function.
> Zero Crossing Rate: The rate of sign-changes (the number of times the signal changes value) of the audio signal during the frame.
#Total number of zero crossings
zero_crossings = librosa.zero_crossings(audio_file, pad=False)
print(sum(zero_crossings))
The Tempo (Beats per Minute) can be retrieved using the librosa.beat.beat_track function.
# Retrieving the Tempo in Pop 19
tempo, _ = librosa.beat.beat_track(y, sr = sr)
print('Tempo:', tempo , '\n')
The next feature extracted is the Spectral Centroids. > Spectral Centroid: a measure used in digital signal processing to characterize a spectrum. It determines the frequency area around which most of the signal energy concentrates.
# Calculate the Spectral Centroids
spectral_centroids = librosa.feature.spectral_centroid(audio_file, sr=sr)[0]
print('Centroids:', spectral_centroids, '\n')
print('Shape of Spectral Centroids:', spectral_centroids.shape, '\n')
# Computing the time variable for visualization
frames = range(len(spectral_centroids))
# Converts frame counts to time (seconds)
t = librosa.frames_to_time(frames)
print('Frames:', frames, '\n')
print('Time:', t)
Now that we have the shape of the spectral centroids as an array and the time variable (from frame counts), we need to create a function that normalizes the data. Normalization is a technique used to adjust the volume of audio files to a standard level which allows the file to be processed clearly. Once it’s normalized we proceed to retrieve the Spectral Rolloff.
> Spectral Rolloff: the frequency under which the cutoff of the total energy of the spectrum is contained, used to distinguish between sounds. The measure of the shape of the signal.
# Function that normalizes the Sound Data
def normalize(x, axis=0):
return sklearn.preprocessing.minmax_scale(x, axis=axis)
# Spectral RollOff Vector
spectral_rolloff = librosa.feature.spectral_rolloff(audio_file, sr=sr)[0]
plt.figure(figsize = (16, 6))
librosa.display.waveplot(audio_file, sr=sr, alpha=0.4, color = '#A300F9');
plt.plot(t, normalize(spectral_rolloff), color='#FFB100');
Using the audio file, we can continue to get the Mel-Frequency Cepstral Coefficients, which are a set of 20 features. In Music Information Retrieval, it’s often used to describe timbre. We will employ the librosa.feature.mfcc function.
mfccs = librosa.feature.mfcc(audio_file, sr=sr)
print('Mel-Frequency Ceptral Coefficient shape:', mfccs.shape)
#Displaying the Mel-Frequency Cepstral Coefficients:
plt.figure(figsize = (16, 6))
librosa.display.specshow(mfccs, sr=sr, x_axis='time', cmap = 'cool');
The MFCC shape is (20, 1,293), which means that the librosa.feature.mfcc function computed 20 coefficients over 1,293 frames.
mfccs = sklearn.preprocessing.scale(mfccs, axis=1)
print('Mean:', mfccs.mean(), '\n')
print('Var:', mfccs.var())
plt.figure(figsize = (16, 6))
librosa.display.specshow(mfccs, sr=sr, x_axis='time', cmap = 'cool');
Now we retrieve the Chroma Frequencies, using librosa.feature.chroma_stft. > Chroma Frequencies (or Features): are a powerful tool for analyzing music by categorizing pitches. These features capture harmonic and melodic characteristics of music.
# Increase or decrease hop_length to change how granular you want your data to be
hop_length = 5000
# Chromogram
chromagram = librosa.feature.chroma_stft(audio_file, sr=sr, hop_length=hop_length)
print('Chromogram shape:', chromagram.shape)
plt.figure(figsize=(16, 6))
librosa.display.specshow(chromagram, x_axis='time', y_axis='chroma', hop_length=hop_length, cmap='coolwarm');
The output:
Exploratory Data Analysis
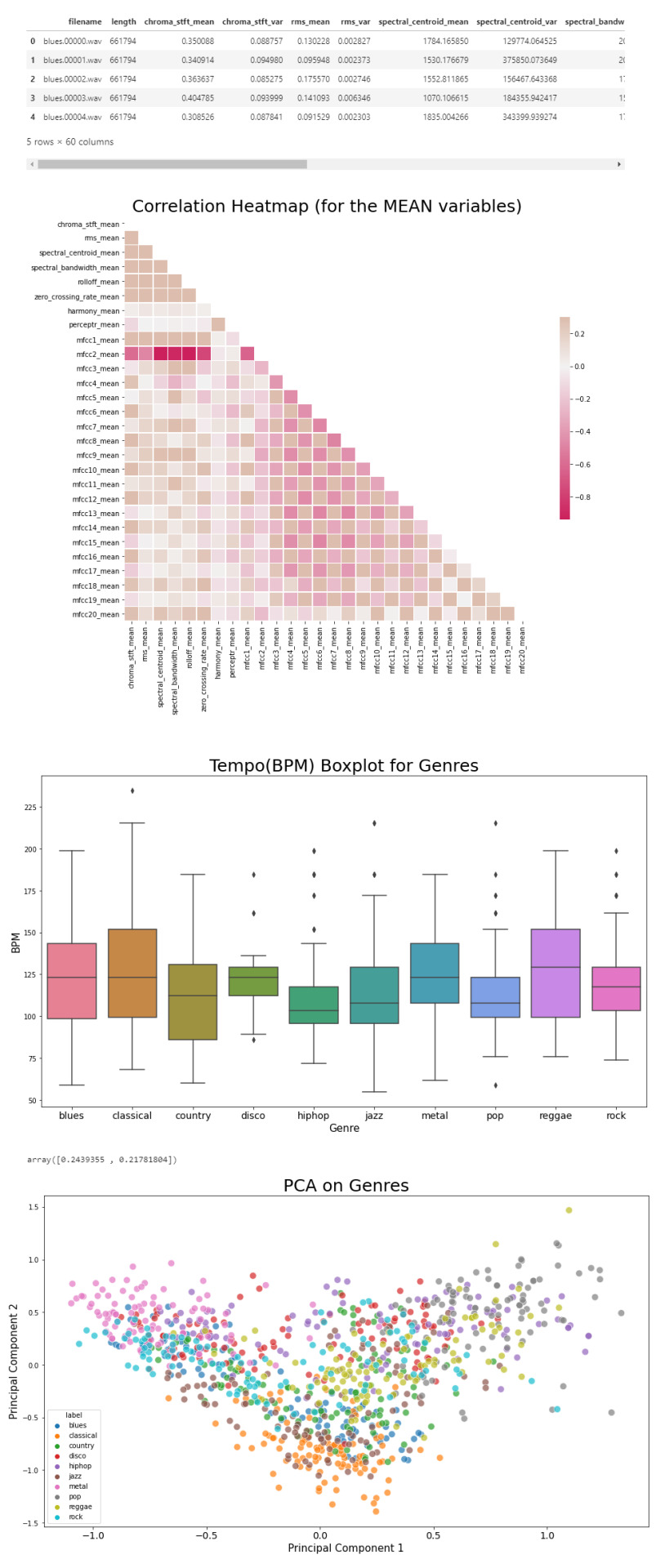
Now that we have a visual understanding of what an audio file looks like, and we’ve explored a good set of features, we can perform EDA, or Exploratory Data Analysis. This is all about getting to know the data and data profiling, summarizing the dataset through descriptive statistics. We can do this by getting a description of the data, using the describe() function or head() function. The describe() function will give us a description of all the dataset rows, and the head() function will give us the written data. We will perform EDA on the csv file, which contains all of the features previously analyzed above, and use the head() function:
# Loading the CSV file
data = pd.read_csv(f'{general_path}/features_30_sec.csv')
data.head()
Now we can create the correlation matrix of the data found in the csv file, using the feature means (average). We do this to summarize our data and pass it into a Correlation Heatmap.
# Computing the Correlation Matrix
spike_cols = [col for col in data.columns if 'mean' in col]
corr = data[spike_cols].corr()
The corr() function finds a pairwise correlation of all columns, excluding non-numeric and null values.
Now we can plot the heatmap:
# Generate a mask for the upper triangle
mask = np.triu(np.ones_like(corr, dtype=np.bool))
# Set up the matplotlib figure
f, ax = plt.subplots(figsize=(16, 11));
# Generate a custom diverging colormap
cmap = sns.diverging_palette(0, 25, as_cmap=True, s = 90, l = 45, n = 5)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5}
plt.title('Correlation Heatmap (for the MEAN variables)', fontsize = 25)
plt.xticks(fontsize = 10)
plt.yticks(fontsize = 10);
Now we will take the data and, extracting the label(genre) and the tempo, we will draw a Box Plot. Box Plots visually show the distribution of numerical data through displaying percentiles and averages.
# Setting the axis for the box plot
x = data[["label", "tempo"]]
f, ax = plt.subplots(figsize=(16, 9));
sns.boxplot(x = "label", y = "tempo", data = x, palette = 'husl');
plt.title('Tempo(BPM) Boxplot for Genres', fontsize = 25)
plt.xticks(fontsize = 14)
plt.yticks(fontsize = 10);
plt.xlabel("Genre", fontsize = 15)
plt.ylabel("BPM", fontsize = 15)
Now we will draw a Scatter Diagram. To do this, we need to visualize possible groups of genres:
# To visualize possible groups of genres
data = data.iloc[0:, 1:]
y = data['label']
X = data.loc[:, data.columns != 'label']
We use data.iloc to get rows and columns at integer locations, and data.loc to get rows and columns with particular labels, excluding the label column. The next step is to normalize our data:
# Normalization
cols = X.columns
min_max_scaler = preprocessing.MinMaxScaler()
np_scaled = min_max_scaler.fit_transform(X)
X = pd.DataFrame(np_scaled, columns = cols)
Using the preprocessing library, we rescale each feature to a given range. Then we add a fit to data and transform (fit_transform).
We can proceed with a Principal Component Analysis:
# Principal Component Analysis
pca = PCA(n_components=2)
principalComponents = pca.fit_transform(X)
principalDf = pd.DataFrame(data = principalComponents, columns = ['principal component 1', 'principal component 2'])
# concatenate with target label
finalDf = pd.concat([principalDf, y], axis = 1)
PCA is used to reduce dimensionality in data. The fit learns some quantities from the data. Before the fit transform, the data shape was [1000, 58], meaning there’s 1000 rows with 58 columns (in the CSV file there’s 60 columns but two of these are string values, so it leaves with 58 numeric columns).
Once we use the PCA function, and set the components number to 2 we reduce the dimension of our project from 58 to 2. We have found the optimal stretch and rotation in our 58-dimension space to see the layout in two dimensions.
After reducing the dimensional space, we lose some variance(information).
pca.explained_variance_ratio_
By using this attribute we get the explained variance ratio, which we sum to get the percentage. In this case the variance explained is 46.53% .
plt.figure(figsize = (16, 9))
sns.scatterplot(x = "principal component 1", y = "principal component 2", data = finalDf, hue = "label", alpha = 0.7,
s = 100);
plt.title('PCA on Genres', fontsize = 25)
plt.xticks(fontsize = 14)
plt.yticks(fontsize = 10);
plt.xlabel("Principal Component 1", fontsize = 15)
plt.ylabel("Principal Component 2", fontsize = 15)
plt.savefig("PCA Scattert.jpg")
The output:
Genre Classification
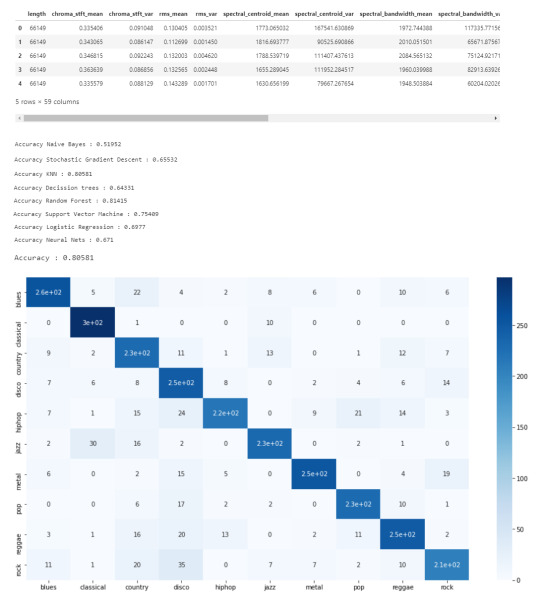
Now we know what our data looks like, the features it has and have analyzed the principal component on all genres. All we have left to do is to build a classifier model that will predict any new audio data input its genre. We will use the CSV with 10 times the data for this.
# Load the data
data = pd.read_csv(f'{general_path}/features_3_sec.csv')
data = data.iloc[0:, 1:]
data.head()
Once again visualizing and normalizing the data.
y = data['label'] # genre variable.
X = data.loc[:, data.columns != 'label'] #select all columns but not the labels
# Normalization
cols = X.columns
min_max_scaler = preprocessing.MinMaxScaler()
np_scaled = min_max_scaler.fit_transform(X)
# new data frame with the new scaled data.
X = pd.DataFrame(np_scaled, columns = cols)
Now we have to split the data for training. Like I did in my previous post, the proportions are (70:30). 70% of the data will be used for training and 30% of the data will be used for testing.
# Split the data for training
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
I tested 7 algorithms but I decided to go with K Nearest-Neighbors because I had previously used it.
knn = KNeighborsClassifier(n_neighbors=19)
knn.fit(X_train, y_train)
preds = knn.predict(X_test)
print('Accuracy', ':', round(accuracy_score(y_test, preds), 5), '\n')
# Confusion Matrix
confusion_matr = confusion_matrix(y_test, preds) #normalize = 'true'
plt.figure(figsize = (16, 9))
sns.heatmap(confusion_matr, cmap="Blues", annot=True,
xticklabels = ["blues", "classical", "country", "disco", "hiphop", "jazz", "metal", "pop", "reggae", "rock"],
yticklabels=["blues", "classical", "country", "disco", "hiphop", "jazz", "metal", "pop", "reggae", "rock"]);
The output:
youtube
References
· https://medium.com/@james_52456/machine-learning-and-the-future-of-music-an-era-of-ml-artists-9be5ef27b83e
· https://www.kaggle.com/andradaolteanu/work-w-audio-data-visualise-classify-recommend/
· https://www.kaggle.com/dapy15/music-genre-classification/notebook
· https://towardsdatascience.com/how-to-start-implementing-machine-learning-to-music-4bd2edccce1f
· https://en.wikipedia.org/wiki/Music_information_retrieval
· https://pandas.pydata.org
· https://scikit-learn.org/
· https://seaborn.pydata.org
· https://matplotlib.org
· https://librosa.org/doc/main/index.html
· https://github.com/dmlc/xgboost
· https://docs.python.org/3/library/os.html
· https://www.tensorflow.org/
· https://www.hindawi.com/journals/sp/2021/1651560/
0 notes
Text
Anjuum Khanna – Top 3 Machine Learning Projects for Beginners

Anjuum Khanna – In the IT sector, it is more helpful to work on practical projects than theoretical knowledge. It is important to get theoretical knowledge, but in the end, this knowledge we will apply in our projects. Working on real world projects helps us with how the algorithm works, if we made a slight change to this code how it would affect the projects.
In this blog post, you will discover how beginners like you can gain incredible progress in applying Machine learning to real-world problems with these awesome machine learning projects for beginners recommended by Anjuum Khanna.
Top 3 machine learning projects for beginners that cover the core aspects of machine learning such as regression, unsupervised learning. In all these machine learning projects you will start with real world datasets that are freely accessible.
Top 3 Machine Learning Projects for Beginners
1) Sales Forecasting using Walmart Dataset
This project is available on github, created by Gagandeep Singh Khanju, This is a Regression based modelling project to forecast the sales of Walmart. This project was created on Jupyter notebook, and for this project he used the “Walmart Store Sales Forecasting” dataset, which was available on Kaggle. Walmart is probably the biggest retailer worldwide and it is significant for them to have precise conjectures for their deals in different departments. Since there can be numerous components that can influence the deals for each division, it becomes basic that he distinguish the key factors that have an impact in driving the deals and use them to build up a model that can help in estimating the deals with some exactness. According to him “ In this project, he conducted multiple linear regression to predict the future sales. There were several different factors that he analyzed in his regression model starting with a full model with all the variables and then moving towards a reduced model by eliminating insignificant variables. He used several different exploratory analyses to identify the key variables for his regression equation such as correlation plots, heatmaps, histograms etc.”
2) BigMart Sales Predictions
This project is available on github, created by Gurudev Aradhye. This is a Regression based modelling project which can be tried to solve using two approaches XGBoost with hypertunning and Random forest with hypertunning. This project was created on Jupyter notebook, packages which he used in the project are pandas, numpy, sklearn, matplotlib and for this project you can use the “BigMart Sales predictions” dataset, which was available on Kaggle. According to him, “These two algorithms had their own importance and uses. The XGBoost is used in many competitions. Here hypertunning is performed with Greedy Search which initially takes some initial parameter values then it will search for parameter values which increases the accuracy of the model. Some details about problems are, The goal is to find item sales at Outlet of different types & located at different locations, It includes tasks such as data visualization, cleaning and transformation, feature engineering.
3) Music Recommendation system
This project is available on Github, created by Sarath Sattiraju. This is a simple Music Recommendation System based on an unsupervised learning system which analyses multiple users playlists and gives recommendations for a particular playlist of a user. This model is a user-to-user based recommendation system. The dataset considered for this project is the music analysis dataset FMA. This project was created on Jupyter notebook, Clustering algorithms were used to provide predictions for the data. Recommendations were given based on the frequent genre, frequent artist, top 10 songs.
About Anjuum Khanna, Tech Blogger
Anjuum Khanna a strategic leader with a proven track record of over 19 years in spread heading profitable ventures within Fintech, eCom Startups, BPOs, Telecom & D2H, spearheaded domestic & Global Business Operations with large team sizes. Championed change management & enterprise wise automation initiatives within organizations in India & Middle East. Presently working as Vice President at Mswipe Technologies.
Explore more Blogs:
Anjuum Khanna – How Robotics, AI and Automation Are shaping the future of World
Anjuum Khanna – 4 AI Projects That Cover All Basics
Anjuum Khanna – Top 5 most popular machine learning tools
visit : https://anjuumkhanna.in/
#anjuum khanna blogs#anjuum khanna tech blogger#anjuum khanna consultant#anjuum khanna#anjuum khanna machine learning tools#anjuum khanna machine learning projects
0 notes
Text
machine learning study resources from ocdevel by Tyler Renelle
basic algorithms
Tour of Machine Learning Algorithms - link
The Master Algorithm - book
math
KhanAcademy:
Either LinAlg course:medium OR Fast.ai course:medium
Stats course:medium
Calc course:medium
Books
Introduction to Linear Algebra book:hard
All of statistics book:hard
Calculus book:hard
Audio (supplementary material)
Statistics, Probability audio|course:hard
Calculus 1, 2, 3 audio|course:hard
Mathematical Decision Making audio|course:hard course on "Operations Research", similar to ML
Information Theory audio|course:hard
deep learining
Resources
Deep Learning Simplified video:easy quick series to get a lay-of-the-land.
TensorFlow Tutorials tutorial:medium
Fast.ai course:medium practical DL for coders
Hands-On Machine Learning with Scikit-Learn and TensorFlow book:medium
Deep Learning Book (Free HTML version) book:hard comprehensive DL bible; highly mathematical
Languages & Frameworks
Resources
Python book:medium
Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython 2nd Edition book:easy
TensorFlow Tutorials tutorial:medium
Hands-On Machine Learning with Scikit-Learn and TensorFlow book:medium
Checkpoint
45m/d ML
Coursera course:hard
Python book:medium
Deep Learning Resources
15m/d Math (KhanAcademy)
Either LinAlg course:medium OR Fast.ai course:medium
Stats course:medium
Calc course:medium
Audio
The Master Algorithm audio:medium Semi-technical overview of ML basics & main algorithms
Mathematical Decision Making audio|course:hard course on "Operations Research", similar to ML
Statistics, Probability audio|course:hard
Calculus 1, 2, 3 audio|course:hard
Shallow Algos 1
Resources
Tour of Machine Learning Algorithms article:easy
Elements of Statistical Learning book:hard
Pattern Recognition and Machine Learning (Free PDF?) book:hard
Hands-On Machine Learning with Scikit-Learn and TensorFlow book:medium (replaced R book)
Which algo to use?
Pros/cons table for algos picture
Decision tree of algos picture
Mathematical Decision Making audio|course:hard course on "Operations Research", similar to ML
Consciousness
Resources
Philosophy of Mind: Brains, Consciousness, and Thinking Machines (Audible, TGC) audio:easy
Natural Language Processing 1
Resources
Speech and Language Processing book:hard comprehensive classical-NLP bible
Stanford NLP YouTube course|audio:medium If offline, skip to the Deep NLP playlist (see tweet).
NLTK Book book:medium
Deep NLP 1
Resources
Overview Articles:
Stanford cs224n: Deep NLP course:medium (replaces cs224d)
TensorFlow Tutorials tutorial:medium (start at Word2Vec + next 2 pages)
Deep Learning Resources
Unreasonable Effectiveness of RNNs article:easy
Deep Learning, NLP, and Representations article:medium
Understanding LSTM Networks article:medium
Deep Learning Book (Free HTML version) book:hard comprehensive DL bible; highly mathematical
Fast.ai course:medium practical DL for coders
Convolutional Neural Networks
Resources
Stanford cs231n: Convnets course:medium
Reinforcement Learning Intro
Resources
AI a Modern Approach. Website, Book book:hard
Berkeley cs294: Deep Reinforcement Learning course:hard
RL Course by David Silver course|audio:hard
0 notes
Text







Python Numpy Tutorials
#numpy tutorials#numpy for beginners#numpy arrays#what is array in numpy#numpy full array#how to create numpy full array#what is numpy full array#how to use numpy full array#uses of numpy full array#how to define the shape of numpy array#python for beginners#python full course#numpy full course#numpy python playlist#numpy playlist#complete python numpy tutorials#numpy full array function#python array#python numpy library#how to create arrays in python numpy
0 notes
Link
Businesses and organizations are increasingly using video and audio content for a variety of functions, such as advertising, customer service, media post-production, employee training, and education. As the volume of multimedia content generated by these activities proliferates, businesses are demanding high-quality transcripts of video and audio to organize files, enable text queries, and improve accessibility to audiences who are deaf or hard of hearing (466 million with disabling hearing loss worldwide) or language learners (1.5 billion English language learners worldwide).
Traditional speech-to-text transcription methods typically involve manual, time-consuming, and expensive human labor. Powered by machine learning (ML), Amazon Transcribe is a speech-to-text service that delivers high-quality, low-cost, and timely transcripts for business use cases and developer applications. In the case of transcribing domain-specific terminologies in fields such as legal, financial, construction, higher education, or engineering, the custom vocabularies feature can improve transcription quality. To use this feature, you create a list of domain-specific terms and reference that vocabulary file when running transcription jobs.
This post shows you how to use Amazon Augmented AI (Amazon A2I) to help generate this list of domain-specific terms by sending low-confidence predictions from Amazon Transcribe to humans for review. We measure the word error rate (WER) of transcriptions and number of correctly-transcribed terms to demonstrate how to use custom vocabularies to improve transcription of domain-specific terms in Amazon Transcribe.
To complete this use case, use the notebook A2I-Video-Transcription-with-Amazon-Transcribe.ipynb on the Amazon A2I Sample Jupyter Notebook GitHub repo.
Example of mis-transcribed annotation of the technical term, “an EC2 instance”. This term was transcribed as “Annecy two instance”.
Example of correctly transcribed annotation of the technical term “an EC2 instance” after using Amazon A2I to build an Amazon Transcribe custom vocabulary and re-transcribing the video.
This walkthrough focuses on transcribing video content. You can modify the code provided to use audio files (such as MP3 files) by doing the following:
Upload audio files to your Amazon Simple Storage Service (Amazon S3) bucket and using them in place of the video files provided.
Modify the button text and instructions in the worker task template provided in this walkthrough and tell workers to listen to and transcribe audio clips.
Solution overview
The following diagram presents the solution architecture.
We briefly outline the steps of the workflow as follows:
Perform initial transcription. You transcribe a video about Amazon SageMaker, which contains multiple mentions of technical ML and AWS terms. When using Amazon Transcribe out of the box, you may find that some of these technical mentions are mis-transcribed. You generate a distribution of confidence scores to see the number of terms that Amazon Transcribe has difficulty transcribing.
Create human review workflows with Amazon A2I. After you identify words with low-confidence scores, you can send them to a human to review and transcribe using Amazon A2I. You can make yourself a worker on your own private Amazon A2I work team and send the human review task to yourself so you can preview the worker UI and tools used to review video clips.
Build custom vocabularies using A2I results. You can parse the human-transcribed results collected from Amazon A2I to extract domain-specific terms and use these terms to create a custom vocabulary table.
Improve transcription using custom vocabulary. After you generate a custom vocabulary, you can call Amazon Transcribe again to get improved transcription results. You evaluate and compare the before and after performances using an industry standard called word error rate (WER).
Prerequisites
Before beginning, you need the following:
An AWS account.
An S3 bucket. Provide its name in BUCKET in the notebook. The bucket must be in the same Region as this Amazon SageMaker notebook instance.
An AWS Identity and Access Management (IAM) execution role with required permissions. The notebook automatically uses the role you used to create your notebook instance (see the next item in this list). Add the following permissions to this IAM role:
Attach managed policies AmazonAugmentedAIFullAccess and AmazonTranscribeFullAccess.
When you create your role, you specify Amazon S3 permissions. You can either allow that role to access all your resources in Amazon S3, or you can specify particular buckets. Make sure that your IAM role has access to the S3 bucket that you plan to use in this use case. This bucket must be in the same Region as your notebook instance.
An active Amazon SageMaker notebook instance. For more information, see Create a Notebook Instance. Open your notebook instance and upload the notebook A2I-Video-Transcription-with-Amazon-Transcribe.ipynb.
A private work team. A work team is a group of people that you select to review your documents. You can choose to create a work team from a workforce, which is made up of workers engaged through Amazon Mechanical Turk, vendor-managed workers, or your own private workers that you invite to work on your tasks. Whichever workforce type you choose, Amazon A2I takes care of sending tasks to workers. For this post, you create a work team using a private workforce and add yourself to the team to preview the Amazon A2I workflow. For instructions, see Create a Private Workforce. Record the ARN of this work team—you need it in the accompanying Jupyter notebook.
To understand this use case, the following are also recommended:
Basic understanding of AWS services like Amazon Transcribe, its features such as custom vocabularies, and the core components and workflow Amazon A2I uses.
The notebook uses the AWS SDK for Python (Boto3) to interact with these services.
Familiarity with Python and NumPy.
Basic familiarity with Amazon S3.
Getting started
After you complete the prerequisites, you’re ready to deploy this solution entirely on an Amazon SageMaker Jupyter notebook instance. Follow along in the notebook for the complete code.
To start, follow the Setup code cells to set up AWS resources and dependencies and upload the provided sample MP4 video files to your S3 bucket. For this use case, we analyze videos from the official AWS playlist on introductory Amazon SageMaker videos, also available on YouTube. The notebook walks through transcribing and viewing Amazon A2I tasks for a video about Amazon SageMaker Jupyter Notebook instances. In Steps 3 and 4, we analyze results for a larger dataset of four videos. The following table outlines the videos that are used in the notebook, and how they are used.
Video # Video Title File Name Function
1
Fully-Managed Notebook Instances with Amazon SageMaker – a Deep Dive Fully-Managed Notebook Instances with Amazon SageMaker – a Deep Dive.mp4 Perform the initial transcription and viewing sample Amazon A2I jobs in Steps 1 and 2.Build a custom vocabulary in Step 3
2
Built-in Machine Learning Algorithms with Amazon SageMaker – a Deep Dive Built-in Machine Learning Algorithms with Amazon SageMaker – a Deep Dive.mp4 Test transcription with the custom vocabulary in Step 4
3
Bring Your Own Custom ML Models with Amazon SageMaker Bring Your Own Custom ML Models with Amazon SageMaker.mp4 Build a custom vocabulary in Step 3
4
Train Your ML Models Accurately with Amazon SageMaker Train Your ML Models Accurately with Amazon SageMaker.mp4 Test transcription with the custom vocabulary in Step 4
In Step 4, we refer to videos 1 and 3 as the in-sample videos, meaning the videos used to build the custom vocabulary. Videos 2 and 4 are the out-sample videos, meaning videos that our workflow hasn’t seen before and are used to test how well our methodology can generalize to (identify technical terms from) new videos.
Feel free to experiment with additional videos downloaded by the notebook, or your own content.
Step 1: Performing the initial transcription
Our first step is to look at the performance of Amazon Transcribe without custom vocabulary or other modifications and establish a baseline of accuracy metrics.
Use the transcribe function to start a transcription job. You use vocab_name parameter later to specify custom vocabularies, and it’s currently defaulted to None. See the following code:
transcribe(job_names[0], folder_path+all_videos[0], BUCKET)
Wait until the transcription job displays COMPLETED. A transcription job for a 10–15-minute video typically takes up to 5 minutes.
When the transcription job is complete, the results is stored in an output JSON file called YOUR_JOB_NAME.json in your specified BUCKET. Use the get_transcript_text_and_timestamps function to parse this output and return several useful data structures. After calling this, all_sentences_and_times has, for each transcribed video, a list of objects containing sentences with their start time, end time, and confidence score. To save those to a text file for use later, enter the following code:
file0 = open("originaltranscript.txt","w") for tup in sentences_and_times_1: file0.write(tup['sentence'] + "\n") file0.close()
To look at the distribution of confidence scores, enter the following code:
from matplotlib import pyplot as plt plt.style.use('ggplot') flat_scores_list = all_scores[0] plt.xlim([min(flat_scores_list)-0.1, max(flat_scores_list)+0.1]) plt.hist(flat_scores_list, bins=20, alpha=0.5) plt.title('Plot of confidence scores') plt.xlabel('Confidence score') plt.ylabel('Frequency') plt.show()
The following graph illustrates the distribution of confidence scores.
Next, we filter out the high confidence scores to take a closer look at the lower ones.
You can experiment with different thresholds to see how many words fall below that threshold. For this use case, we use a threshold of 0.4, which corresponds to 16 words below this threshold. Sequences of words with a term under this threshold are sent to human review.
As you experiment with different thresholds and observe the number of tasks it creates in the Amazon A2I workflow, you can see a tradeoff between the number of mis-transcriptions you want to catch and the amount of time and resources you’re willing to devote to corrections. In other words, using a higher threshold captures a greater percentage of mis-transcriptions, but it also increases the number of false positives—low-confidence transcriptions that don’t actually contain any important technical term mis-transcriptions. The good news is that you can use this workflow to quickly experiment with as many different threshold values as you’d like before sending it to your workforce for human review. See the following code:
THRESHOLD = 0.4 # Filter scores that are less than THRESHOLD all_bad_scores = [i for i in flat_scores_list if i < THRESHOLD] print(f"There are {len(all_bad_scores)} words that have confidence score less than {THRESHOLD}") plt.xlim([min(all_bad_scores)-0.1, max(all_bad_scores)+0.1]) plt.hist(all_bad_scores, bins=20, alpha=0.5) plt.title(f'Plot of confidence scores less than {THRESHOLD}') plt.xlabel('Confidence score') plt.ylabel('Frequency') plt.show()
You get the following output:
There are 16 words that have confidence score less than 0.4
The following graph shows the distribution of confidence scores less than 0.4.
As you experiment with different thresholds, you can see a number of words classified with low confidence. As we see later, terms that are specific to highly technical domains are more difficult to automatically transcribe in general, so it’s important that we capture these terms and incorporate them into our custom vocabulary.
Step 2: Creating human review workflows with Amazon A2I
Our next step is to create a human review workflow (or flow definition) that sends low confidence scores to human reviewers and retrieves the corrected transcription they provide. The accompanying Jupyter notebook contains instructions for the following steps:
Create a workforce of human workers to review predictions. For this use case, creating a private workforce enables you to send Amazon A2I human review tasks to yourself so you can preview the worker UI.
Create a work task template that is displayed to workers for every task. The template is rendered with input data you provide, instructions to workers, and interactive tools to help workers complete your tasks.
Create a human review workflow, also called a flow definition. You use the flow definition to configure details about your human workforce and the human tasks they are assigned.
Create a human loop to start the human review workflow, sending data for human review as needed. In this example, you use a custom task type and start human loop tasks using the Amazon A2I Runtime API. Each time StartHumanLoop is called, a task is sent to human reviewers.
In the notebook, you create a human review workflow using the AWS Python SDK (Boto3) function create_flow_definition. You can also create human review workflows on the Amazon SageMaker console.
Setting up the worker task UI
Amazon A2I uses Liquid, an open-source template language that you can use to insert data dynamically into HTML files.
In this use case, we want each task to enable a human reviewer to watch a section of the video where low confidence words appear and transcribe the speech they hear. The HTML template consists of three main parts:
A video player with a replay button that only allows the reviewer to play the specific subsection
A form for the reviewer to type and submit what they hear
Logic written in JavaScript to give the replay button its intended functionality
The following code is the template you use:
<head> <style> h1 { color: black; font-family: verdana; font-size: 150%; } </style> </head> <script src="https://assets.crowd.aws/crowd-html-elements.js"></script> <crowd-form> <video id="this_vid"> <source src="" type="audio/mp4"> Your browser does not support the audio element. </video> <br /> <br /> <crowd-button onclick="onClick(); return false;"><h1> Click to play video section!</h1></crowd-button> <h3>Instructions</h3> <p>Transcribe the audio clip </p> <p>Ignore "umms", "hmms", "uhs" and other non-textual phrases. </p> <p>The original transcript is <strong>""</strong>. If the text matches the audio, you can copy and paste the same transcription.</p> <p>Ignore "umms", "hmms", "uhs" and other non-textual phrases. If a word is cut off in the beginning or end of the video clip, you do NOT need to transcribe that word. You also do NOT need to transcribe punctuation at the end of clauses or sentences. However, apostrophes and punctuation used in technical terms should still be included, such as "Denny's" or "file_name.txt"</p> <p><strong>Important:</strong> If you encounter a technical term that has multiple words, please <strong>hyphenate</strong> those words together. For example, "k nearest neighbors" should be transcribed as "k-nearest-neighbors."</p> <p>Click the space below to start typing.</p> <full-instructions header="Transcription Instructions"> <h2>Instructions</h2> <p>Click the play button and listen carefully to the audio clip. Type what you hear in the box below. Replay the clip by clicking the button again, as many times as needed.</p> </full-instructions> </crowd-form> <script> var video = document.getElementById('this_vid'); video.onloadedmetadata = function() { video.currentTime = ; }; function onClick() { video.pause(); video.currentTime = ; video.play(); video.ontimeupdate = function () { if (video.currentTime >= ) { video.pause() } } } </script>
The field allows you to grant access to and display a video to workers using a path to the video’s location in an S3 bucket. To prevent the reviewer from navigating to irrelevant sections of the video, the controls parameter is omitted from the video tag and a single replay button is included to control which section can be replayed.
Under the video player, the <crowd-text-area> HTML tag creates a submission form that your reviewer uses to type and submit.
At the end of the HTML snippet, the section enclosed by the <script> tag contains the JavaScript logic for the replay button. The and fields allow you to inject the start and end times of the video subsection you want transcribed for the current task.
You create a worker task template using the AWS Python SDK (Boto3) function create_human_task_ui. You can also create a human task template on the Amazon SageMaker console.
Creating human loops
After setting up the flow definition, we’re ready to use Amazon Transcribe and initiate human loops. While iterating through the list of transcribed words and their confidence scores, we create a human loop whenever the confidence score is below some threshold, CONFIDENCE_SCORE_THRESHOLD. A human loop is just a human review task that allows workers to review the clips of the video that Amazon Transcribe had difficulty with.
An important thing to consider is how we deal with a low-confidence word that is part of a phrase that was also mis-transcribed. To handle these cases, you use a function that gets the sequence of words centered about a given index, and the sequence’s starting and ending timestamps. See the following code:
def get_word_neighbors(words, index): """ gets the words transcribe found at most 3 away from the input index Returns: list: words at most 3 away from the input index int: starting time of the first word in the list int: ending time of the last word in the list """ i = max(0, index - 3) j = min(len(words) - 1, index + 3) return words[i: j + 1], words[i]["start_time"], words[j]["end_time"]
For every word we encounter with low confidence, we send its associated sequence of neighboring words for human review. See the following code:
human_loops_started = [] CONFIDENCE_SCORE_THRESHOLD = THRESHOLD i = 0 for obj in confidences_1: word = obj["content"] neighbors, start_time, end_time = get_word_neighbors(confidences_1, i) # Our condition for when we want to engage a human for review if (obj["confidence"] < CONFIDENCE_SCORE_THRESHOLD): # get the original sequence of words sequence = "" for block in neighbors: sequence += block['content'] + " " humanLoopName = str(uuid.uuid4()) # "initialValue": word, inputContent = { "filePath": job_uri_s3, "start_time": start_time, "end_time": end_time, "original_words": sequence } start_loop_response = a2i.start_human_loop( HumanLoopName=humanLoopName, FlowDefinitionArn=flowDefinitionArn, HumanLoopInput={ "InputContent": json.dumps(inputContent) } ) human_loops_started.append(humanLoopName) # print(f'Confidence score of {obj["confidence"]} is less than the threshold of {CONFIDENCE_SCORE_THRESHOLD}') # print(f'Starting human loop with name: {humanLoopName}') # print(f'Sending words from times {start_time} to {end_time} to review') print(f'The original transcription is ""{sequence}"" \n') i=i+1
For the first video, you should see output that looks like the following code:
========= Fully-Managed Notebook Instances with Amazon SageMaker - a Deep Dive.mp4 ========= The original transcription is "show up Under are easy to console " The original transcription is "And more cores see is compute optimized " The original transcription is "every version of Annecy two instance is " The original transcription is "distributing data sets wanted by putt mode " The original transcription is "onto your EBS volumes And again that's " The original transcription is "of those example No books are open " The original transcription is "the two main ones markdown is gonna " The original transcription is "I started using Boto three but I " The original transcription is "absolutely upgrade on bits fun because you " The original transcription is "That's the python Asi que We're getting " The original transcription is "the Internet s Oh this is from " The original transcription is "this is from Sarraf He's the author " The original transcription is "right up here then the title of " The original transcription is "but definitely use Lambda to turn your " The original transcription is "then edit your ec2 instance or the " Number of tasks sent to review: 15
As you’re completing tasks, you should see these mis-transcriptions with the associated video clips. See the following screenshot.
Human loop statuses that are complete display Completed. It’s not required to complete all human review tasks before continuing. Having 3–5 finished tasks is typically sufficient to see how technical terms can be extracted from the results. See the following code:
completed_human_loops = [] for human_loop_name in human_loops_started: resp = a2i.describe_human_loop(HumanLoopName=human_loop_name) print(f'HumanLoop Name: {human_loop_name}') print(f'HumanLoop Status: {resp["HumanLoopStatus"]}') print(f'HumanLoop Output Destination: {resp["HumanLoopOutput"]}') print('\n') if resp["HumanLoopStatus"] == "Completed": completed_human_loops.append(resp)
When all tasks are complete, Amazon A2I stores results in your S3 bucket and sends an Amazon CloudWatch event (you can check for these on your AWS Management Console). Your results should be available in the S3 bucket OUTPUT_PATH when all work is complete. You can print the results with the following code:
import re import pprint pp = pprint.PrettyPrinter(indent=4) for resp in completed_human_loops: splitted_string = re.split('s3://' + BUCKET + '/', resp['HumanLoopOutput']['OutputS3Uri']) output_bucket_key = splitted_string[1] response = s3.get_object(Bucket=BUCKET, Key=output_bucket_key) content = response["Body"].read() json_output = json.loads(content) pp.pprint(json_output) print('\n')
Step 3: Improving transcription using custom vocabulary
You can use the corrected transcriptions from our human reviewers to parse the results to identify the domain-specific terms you want to add to a custom vocabulary. To get a list of all human-reviewed words, enter the following code:
corrected_words = [] for resp in completed_human_loops: splitted_string = re.split('s3://' + BUCKET + '/', resp['HumanLoopOutput']['OutputS3Uri']) output_bucket_key = splitted_string[1] response = s3.get_object(Bucket=BUCKET, Key=output_bucket_key) content = response["Body"].read() json_output = json.loads(content) # add the human-reviewed answers split by spaces corrected_words += json_output['humanAnswers'][0]['answerContent']['transcription'].split(" ")
We want to parse through these words and look for uncommon English words. An easy way to do this is to use a large English corpus and verify if our human-reviewed words exist in this corpus. In this use case, we use an English-language corpus from Natural Language Toolkit (NLTK), a suite of open-source, community-driven libraries for natural language processing research. See the following code:
# Create dictionary of English words # Note that this corpus of words is not 100% exhaustive import nltk nltk.download('words') from nltk.corpus import words my_dict=set(words.words()) word_set = set([]) for word in remove_contractions(corrected_words): if word: if word.lower() not in my_dict: if word.endswith('s') and word[:-1] in my_dict: print("") elif word.endswith("'s") and word[:-2] in my_dict: print("") else: word_set.add(word) for word in word_set: print(word)
The words you find may vary depending on which videos you’ve transcribed and what threshold you’ve used. The following code is an example of output from the Amazon A2I results of the first and third videos from the playlist (see the Getting Started section earlier):
including machine-learning grabbing amazon boto3 started t3 called sarab ecr using ebs internet jupyter distributing opt/ml optimized desktop tokenizing s3 sdk encrypted relying sagemaker datasets upload iam gonna managing wanna vpc managed mars.r ec2 blazingtext
With these technical terms, you can now more easily manually create a custom vocabulary of those terms that we want Amazon Transcribe to recognize. You can use a custom vocabulary table to tell Amazon Transcribe how each technical term is pronounced and how it should be displayed. For more information on custom vocabulary tables, see Create a Custom Vocabulary Using a Table.
While you process additional videos on the same topic, you can keep updating this list, and the number of new technical terms you have to add will likely decrease each time you get a new video.
We built a custom vocabulary (see the following code) using parsed Amazon A2I results from the first and third videos with a 0.5 THRESHOLD confidence value. You can use this vocabulary for the rest of the notebook:
finalized_words=[['Phrase','IPA','SoundsLike','DisplayAs'], # This top line denotes the column headers of the text file. ['machine-learning','','','machine learning'], ['amazon','','am-uh-zon','Amazon'], ['boto-three','','boe-toe-three','Boto3'], ['T.-three','','tee-three','T3'], ['Sarab','','suh-rob','Sarab'], ['E.C.R.','','ee-see-are','ECR'], ['E.B.S.','','ee-bee-ess','EBS'], ['jupyter','','joo-pih-ter','Jupyter'], ['opt-M.L.','','opt-em-ell','/opt/ml'], ['desktop','','desk-top','desktop'], ['S.-Three','','ess-three','S3'], ['S.D.K.','','ess-dee-kay','SDK'], ['sagemaker','','sage-may-ker','SageMaker'], ['mars-dot-r','','mars-dot-are','mars.R'], ['I.A.M.','','eye-ay-em','IAM'], ['V.P.C.','','','VPC'], ['E.C.-Two','','ee-see-too','EC2'], ['blazing-text','','','BlazingText'], ]
After saving your custom vocabulary table to a text file and uploading it to an S3 bucket, create your custom vocabulary with a specified name so Amazon Transcribe can use it:
# The name of your custom vocabulary must be unique! vocab_improved='sagemaker-custom-vocab' transcribe = boto3.client("transcribe") response = transcribe.create_vocabulary( VocabularyName=vocab_improved, LanguageCode='en-US', VocabularyFileUri='s3://' + BUCKET + '/' + custom_vocab_file_name ) pp.pprint(response)
Wait until the VocabularyState displays READY before continuing. This typically takes up to a few minutes. See the following code:
# Wait for the status of the vocab you created to finish while True: response = transcribe.get_vocabulary( VocabularyName=vocab_improved ) status = response['VocabularyState'] if status in ['READY', 'FAILED']: print(status) break print("Not ready yet...") time.sleep(5)
Step 4: Improving transcription using custom vocabulary
After you create your custom vocabulary, you can call your transcribe function to start another transcription job, this time with your custom vocabulary. See the following code:
job_name_custom_vid_0='AWS-custom-0-using-' + vocab_improved + str(time_now) job_names_custom = [job_name_custom_vid_0] transcribe(job_name_custom_vid_0, folder_path+all_videos[0], BUCKET, vocab_name=vocab_improved)
Wait for the status of your transcription job to display COMPLETED again.
Write the new transcripts to new .txt files with the following code:
# Save the improved transcripts i = 1 for list_ in all_sentences_and_times_custom: file = open(f"improved_transcript_{i}.txt","w") for tup in list_: file.write(tup['sentence'] + "\n") file.close() i = i + 1
Results and analysis
Up to this point, you may have completed this use case with a single video. The remainder of this post refers to the four videos that we used to analyze the results of this workflow. For more information, see the Getting Started section at the beginning of this post.
To analyze metrics on a larger sample size for this workflow, we generated a ground truth transcript in advance, a transcription before the custom vocabulary, and a transcription after the custom vocabulary for each video in the playlist.
The first and third videos are the in-sample videos used to build the custom vocabulary you saw earlier. The second and fourth videos are used as out-sample videos to test Amazon Transcribe again after building the custom vocabulary. Run the associated code blocks to download these transcripts.
Comparing word error rates
The most common metric for speech recognition accuracy is called word error rate (WER), which is defined to be WER =(S+D+I)/N, where S, D, and I are the number of substitution, deletion, and insertion operations, respectively, needed to get from the outputted transcript to the ground truth, and N is the total number of words. This can be broadly interpreted to be the proportion of transcription errors relative to the number of words that were actually said.
We use a lightweight open-source Python library called JiWER for calculating WER between transcripts. See the following code:
!pip install jiwer from jiwer import wer import jiwer
For more information, see JiWER: Similarity measures for automatic speech recognition evaluation.
We calculate our metrics for the in-sample videos (the videos that were used to build the custom vocabulary). Using the code from the notebook, the following code is the output:
===== In-sample videos ===== Processing video #1 The baseline WER (before using custom vocabularies) is 5.18%. The WER (after using custom vocabularies) is 2.62%. The percentage change in WER score is -49.4%. Processing video #3 The baseline WER (before using custom vocabularies) is 11.94%. The WER (after using custom vocabularies) is 7.84%. The percentage change in WER score is -34.4%.
To calculate our metrics for the out-sample videos (the videos that Amazon Transcribe hasn’t seen before), enter the following code:
===== Out-sample videos ===== Processing video #2 The baseline WER (before using custom vocabularies) is 7.55%. The WER (after using custom vocabularies) is 6.56%. The percentage change in WER score is -13.1%. Processing video #4 The baseline WER (before using custom vocabularies) is 10.91%. The WER (after using custom vocabularies) is 8.98%. The percentage change in WER score is -17.6%.
Reviewing the results
The following table summarizes the changes in WER scores.
If we consider absolute WER scores, the initial WER of 5.18%, for instance, might be sufficiently low for some use cases—that’s only around 1 in 20 words that are mis-transcribed! However, this rate can be insufficient for other purposes, because domain-specific terms are often the least common words spoken (relative to frequent words such as “to,” “and,” or “I”) but the most commonly mis-transcribed. For applications like search engine optimization (SEO) and video organization by topic, you may want to ensure that these technical terms are transcribed correctly. In this section, we look at how our custom vocabulary impacted the transcription rates of several important technical terms.
Metrics for specific technical terms
For this post, ground truth refers to the true transcript that was transcribed by hand, original transcript refers to the transcription before applying the custom vocabulary, and new transcript refers to the transcription after applying the custom vocabulary.
In-sample videos
The following table shows the transcription rates for video 1.
The following table shows the transcription rates for video 3.
Out-sample videos
The following table shows the transcription rates for video 2.
The following table shows the transcription rates for video 4.
Using custom vocabularies resulted in an 80-percentage point or more increase in the number of correctly transcribed technical terms. A majority of the time, using a custom vocabulary resulted in 100% accuracy in transcribing these domain-specific terms. It looks like using custom vocabularies was worth the effort after all!
Cleaning up
To avoid incurring unnecessary charges, delete resources when not in use, including your S3 bucket, human review workflow, transcription job, and Amazon SageMaker notebook instance. For instructions, see the following, respectively:
How do I delete an S3 Bucket?
Delete a Flow Definition
DeleteTranscriptionJob
Cleanup: SageMaker Resources
Conclusion
In this post, you saw how you can use Amazon A2I human review workflows and Amazon Transcribe custom vocabularies to improve automated video transcriptions. This walkthrough allows you to quickly identify domain-specific terms and use these terms to build a custom vocabulary so that future mentions of term are transcribed with greater accuracy, at scale. Transcribing key technical terms correctly may be important for SEO, enabling highly specific textual queries, and grouping large quantities of video or audio files by technical terms.
The full proof-of-concept Jupyter notebook can be found in the GitHub repo. For video presentations, sample Jupyter notebooks, and more information about use cases like document processing, content moderation, sentiment analysis, object detection, text translation, and more, see Amazon Augmented AI Resources.
About the Authors
Jasper Huang is a Technical Writer Intern at AWS and a student at the University of Pennsylvania pursuing a BS and MS in computer science. His interests include cloud computing, machine learning, and how these technologies can be leveraged to solve interesting and complex problems. Outside of work, you can find Jasper playing tennis, hiking, or reading about emerging trends.
Talia Chopra is a Technical Writer in AWS specializing in machine learning and artificial intelligence. She works with multiple teams in AWS to create technical documentation and tutorials for customers using Amazon SageMaker, MxNet, and AutoGluon. In her free time, she enjoys meditating, studying machine learning, and taking walks in nature.
from AWS Machine Learning Blog https://ift.tt/3gs5rnh via A.I .Kung Fu
0 notes
Text
Best Way to Learn Python
Hello fellows, have you ever confused that whether you should learn python or not. Maybe you decided to learn python but didn’t know where to start?
So in this article we’ll guide you about the best way to learn Python.
Why to learn python?
There can be many reasons that can make you start to learn Python. Some of them are as follows:
Easy syntax: Python syntax is very easy to learn than any other programming language out there. If you’re an experienced programmer and new to python you’ll amazed after seeing the easiness of writing code in python. Even if you’re new to programming you can start programming with Python right away.
Readability: In most other programming languages, we use indentation only to help make the code look pretty, but in Python it is required. Whether you’re inside in a loop or declaring some functions you have shift your block of code with certain amount of spaces to indicate what block of code a statement belongs too, which increases readability of a code written in Python.
High level language: Python looks more like a readable, human language than like a low-level language, which gives you ability to program at faster rate than a low-level language will allow you.
Object oriented programming language: Python’s support for object-oriented programming in one of its greatest benefits to new programmers because they will be encountering the same concepts and terminology in their work but python also support structured programming fully. So you can code in any style you want.
Free and cross-platform: Python is both free and open source. It runs on all major operating systems like Windows, Linux and Mac OS X.
Large number of standard libraries: Python contains over than 300 standard library modules which contain modules and classes for a wide variety of programming tasks, which will help us to reduce the length of our code and provide easiness to write code.
Python is everywhere: Yeah you read it right, Python is everywhere. It can be used in server automation. It have several great libraries for building web apps like flask, Django. It is heavily being used in scientific computing, it has several libraries dedicated to specific area in scientific computing like NumPy, SciPy, EarthPy and AstroPy. Python is also used in Game development using the library PyGame which support sound, mouse and keyboard interaction and more. The popular 3D application Maya supports Python. If you want to develop desktop application, then Python comes up with the tkinter module built-in. The companies like Instagram, Amazon, Spotify, Facebook and many other using Python language heavily.
Image Source
What is the Best Way to Learn Python?
Before starting, you’ve to decide that which version of Python you’re going to learn Python 2 or Python 3. To see which one is best to start with please open https://www.thecrazyprogrammer.com/2018/01/difference-python-2-3.html
But if you’re new to Python then we recommend you to start with Python 3 because it is the future of Python.
Get Everything Ready
Before starting with Python you’ve to make an environment where you can write and execute python scripts. To write scripts we can use any text editor like notepad, vim editor, sublime etc. and in order to run the programs, we can use command prompt or terminal but your system should have Python installed in it. If you’re using a Linux distribution like Ubuntu, Fedora, Kali or you are a mac user then you doesn’t have to install Python externally, because most of the Linux based operating systems comes with Python pre-installed in it.
But if you’re using a PC (windows based) then the process of installing Python 3 will be same as we install any other software. To download the Python 3 visit here https://www.python.org/downloads/windows/ and during installation, don’t forget to check the checkbox showing “add python to path”, so you’ll be able to access the Python in command prompt.
However we can also use an IDE where we can write and execute the programs at one place. To check which IDE you should use, please visit https://www.thecrazyprogrammer.com/2018/03/best-python-ides.html
Python Basics
First of all, we’ll talk about the basics of Python. In basics, the topics you’ve to cover are as follows:
Introduction to Python
Python Syntax
Strings and Console Output
Conditionals and Control Flow
Functions
List & Dictionaries
Loops
Introduction to Python
File input and output
Free Courses:
To learn these basics concepts you can take this free online course https://www.codecademy.com/learn/learn-python.
Or you can take this free course from Udacity https://in.udacity.com/course/introduction-to-python–ud1110
Or you can take this free course from Udemy https://www.udemy.com/pythonforbeginnersintro/
Even you doesn’t touch programming before, these courses will help you to teach you all the basics you need to know.
Best Books:
If you prefer reading more than watching videos then these books will help you to learn the basics of Python –
Python Programming for absolute beginners: https://www.amazon.com/Python-Programming-Absolute-Beginner-3rd/dp/1435455002/
Learning Python: https://www.amazon.com/Learning-Python-5th-Mark-Lutz/dp/1449355730/
Free Youtube Videos:
Here are some of the best Youtube playlists that can help you learn Python easily-
Python Tutorials for beginners (ProgrammingKnowledge): https://www.youtube.com/watch?v=41qgdwd3zAg&list=PLS1QulWo1RIaJECMeUT4LFwJ-ghgoSH6n
Python programming Tutorials (thenewboston): https://www.youtube.com/watch?v=HBxCHonP6Ro&list=PL6gx4Cwl9DGAcbMi1sH6oAMk4JHw91mC_
After you learn the basics. Now you’ve to decide what you want to do next. Because Python doesn’t have a specific area. Things you can build with Python are as follows:
Websites: If you’re interested in making websites, then try Django Web Framework, Pyramid, Flask and learn it.
Games: If you’re interested in making games, then try You can make games with graphics and sounds.
Desktop and Mobile application: Kivy, Tkinter, wxWidgets, pyqt, GTK+ or Pyside are used to make multi-touch application for desktop and mobile platforms.
Web scraping: Beautifulsoup is used for gathering information from websites.
Scientific and numeric computing: SciPy, Pandas, Ipython can be used for scientific computing and data analysis.
This is not enough, there are a lot of other things that one can do with Python. But for now we’ll see how to learn the above mentioned topics in Python. Lets see them one by one.
Learn Making Websites with Python
Paid Courses:
Here are the list of courses where you can learn Python Web Development.
1. Complete Python Web Course: It is a paid course offered by Udemy, where you’ll learn building Web application with Python and Flask. In this course you’ll also build 8 web application for better practice.
Link: https://www.udemy.com/the-complete-python-web-course-learn-by-building-8-apps/
2. The Ultimate Beginner’s Guide to Django: Learn how to make and publish websites with Django and Python. They will teach you to make three complete apps and publish one online. It is also a paid course by Udemy.
Link: https://www.udemy.com/the-ultimate-beginners-guide-to-django-python-web-dev-website/
Free Youtube Videos:
Here is the list of some of the best YouTube playlists that can help you to lean Python web development for free.
1. Django Tutorials for Beginners (By thenewboston): So far in this playlist, you will learn the very basics of Django in a very friendly voice of Bucky Roberts.
Link: https://www.youtube.com/watch?v=qgGIqRFvFFk&list=PL6gx4Cwl9DGBlmzzFcLgDhKTTfNLfX1IK
2. Django Tutorials (By Max Goodridge): https://www.youtube.com/watch?list=PLw02n0FEB3E3VSHjyYMcFadtQORvl1Ssj&v=Fc2O3_2kax8
After you’ve completed these courses you’ll get the basic idea how to make websites or web applications using Python. Then start a personal major project and complete it.
Learn Making Games with Python
If you want to develop games with Python you’re gonna end-up with PyGame. To learn how to make games with PyGame follow these courses.
1. Making games with Python & Pygame (By AI Sweigart)– its a 365 pages PDF that will help you to make mini games using PyGame. This pdf is completely free out there. You can download it from here https://inventwithpython.com/makinggames.pdf
But you can’t learn from a book as fast as you can learn with a teacher or from video tutorials. So here is the list of some of the YouTube playlists for games development using PyGame-
2. PyGame – Python Game development (By thenewboston): This video series will teach you all the basics of PyGame that you need.
Link: https://www.youtube.com/watch?v=ujOTNg17LjI&list=PLQVvvaa0QuDdLkP8MrOXLe_rKuf6r80KO
3. Master Python interactively with PyGame (By Udemy): If you have some money in your pocket to learn gaming in Python then it can be your best choice because after completing this course you’ll know all the basics of PyGame and how to use sounds and make your game interactive.
Link: https://www.udemy.com/master-python-interactively-with-pygame-ultimate-bootcamp/
Learn Making Mobile and Desktop Application with Python
As I mentioned above that we can make desktop or mobile application using Tkinter, GTK+, Qt, Kivy or wxWidgets. Here are some of the best courses that will help you to make GUI applicaion using Python.
Its highly recommend to take a paid course from udemy to learn GUI. However there are many free courses available out there but they aren’t teaching enough to make you an expert of GUI Development.
1. Learn Python GUI programming using Qt framework: This 12 hours course will teach you how to write your own complex desktop application. This course is about Python GUI programming and building GUI applications using Python and Qt framework.
Link: https://www.udemy.com/python-gui-programming/
2. Python GUI : From A-to-Z With 2 Final Projects: Learn How To Build A Powerfull GUI in Python programming Using Python And Tkinter.
Link: https://www.udemy.com/python-with-tkinter-basics-advanced-build-2-projects-l/
3. Python Kivy The Full Guide: Learn How To Build A Powerful Android Applications and Games using Python And Kivy. It is also a paid course like above two.
Link: https://www.udemy.com/learn-kivy-from-scratch
So these were some of paid courses that will help you learn a lot. But if you don’t want to spend you single penny then here is some of the best books and YouTube playlists that can help you to learn GUI development using Python.
4. Python GUI with Tkinter (thenewboston): This playlist will help you learn the very basics of Tkinter like how to draw basic widgets like buttons, labels, dropdown menus, frames, checkbox, and many more.
Link: https://www.youtube.com/watch?v=RJB1Ek2Ko_Y&list=PL6gx4Cwl9DGBwibXFtPtflztSNPGuIB_d
5. Kivy application development (sentdex): As we know now that Kivy is used to make android application using Python. This YouTube play will help you to learn the basics of android application using Kivy.
Link: https://www.youtube.com/watch?v=CYNWK2GpwgA&list=PLQVvvaa0QuDe_l6XiJ40yGTEqIKugAdTy
6. PyQT Python GUI application development (sentdex): This playlist will help you to make desktop application using PyQT.
Link: https://www.youtube.com/watch?v=JBME1ZyHiP8&list=PLQVvvaa0QuDdVpDFNq4FwY9APZPGSUyR4
If you prefer reading more than watching then here is the list of books that can help you.
7. Python – GUI Programming (Tkinter): This website (Tutorialspoint) will help you to understand each concept of Tkinter module. Whether you’re new or experienced with Tkinter, it can help you a lot and this is free of cost too. You can download the full course of Tkinter as PDF to learn offline.
Link: http://www.tutorialspoint.com/python/python_gui_programming.htm
Here are some of other resources that can help you.
8. PyQT Tutorial – https://www.tutorialspoint.com/pyqt/index.htm
9. wxPython Tutorial – https://www.tutorialspoint.com/wxpython/index.htm
Learn Web Scraping with Python
After searching a lot I found out the best course which can help you to lean web scraping is Web Scraping with Python: BeautifulSoup, Requests & Selenium by Udemy. None of the youtube playlist can help you this much as this course will do. But this is a paid course and you have to spend some extra money then any other course mentioned above.
Link: https://www.udemy.com/web-scraping-with-python-beautifulsoup/
But again if you’re not willing to spend money then remember you have to practice a lot because without money you’re not gonna learn a lot from youtube playlists.
Here are some of the video links :
Intro to web scrapping with Python and Beautiful Soup: https://youtu.be/XQgXKtPSzUI
Python Tutorial: Web Scraping with BeautifulSoup and Requests – https://youtu.be/ng2o98k983
But still we recommend you to take Udemy paid course.
Learn Scientific Computing with Python
The best way to learn scientific computing (NumPy, Pandas, Seaborn , Matplotlib , Plotly , Scikit-Learn , Machine Learning, Tensorflow , and more) in Python we recommend you to start with any video tutorials to get the basic idea how things work and then learn each single module from a standard book. Because in Videos all the methods or properties of a module can’t be covered. That’s why we recommend you to learn with a Book.
Take this course from udemy first-
1. Python for Data Science and Machine Learning Bootcamp: It have 21 hours of lectures and easily explained.
Link: https://www.udemy.com/python-for-data-science-and-machine-learning-bootcamp/
Then purchase this book from amazon or from your nearest book store.
2. Scientific Computing with Python 3: https://www.amazon.in/Scientific-Computing-Python-Claus-Fuhrer/dp/1786463512
Believe me once you have completed the course and mastered each concept mentioned in this book, you can name your self as a data scientist.
I hope this article will help you to find best resource and best way to learn python. If you have any problem or suggestions related with this article then please comment below.
The post Best Way to Learn Python appeared first on The Crazy Programmer.
0 notes
Text
A Machine Learning Guide for Average Humans
A Machine Learning Guide for Average Humans
Posted by alexis-sanders
//<![CDATA[ (function($) { // code using $ as alias to jQuery $(function() { // Hide the hypotext content. $('.hypotext-content').hide(); // When a hypotext link is clicked. $('a.hypotext.closed').click(function (e) { // custom handling here e.preventDefault(); // Create the class reference from the rel value. var id = '.' + $(this).attr('rel'); // If the content is hidden, show it now. if ( $(id).css('display') == 'none' ) { $(id).show('slow'); if (jQuery.ui) { // UI loaded $(id).effect("highlight", {}, 1000); } } // If the content is shown, hide it now. else { $(id).hide('slow'); } }); // If we have a hash value in the url. if (window.location.hash) { // If the anchor is within a hypotext block, expand it, by clicking the // relevant link. console.log(window.location.hash); var anchor = $(window.location.hash); var hypotextLink = $('#' + anchor.parents('.hypotext-content').attr('rel')); console.log(hypotextLink); hypotextLink.click(); // Wait until the content has expanded before jumping to anchor. //$.delay(1000); setTimeout(function(){ scrollToAnchor(window.location.hash); }, 1000); } }); function scrollToAnchor(id) { var anchor = $(id); $('html,body').animate({scrollTop: anchor.offset().top},'slow'); } })(jQuery); //]]>
Machine learning (ML) has grown consistently in worldwide prevalence. Its implications have stretched from small, seemingly inconsequential victories to groundbreaking discoveries. The SEO community is no exception. An understanding and intuition of machine learning can support our understanding of the challenges and solutions Google's engineers are facing, while also opening our minds to ML's broader implications.
The advantages of gaining an general understanding of machine learning include:
Gaining empathy for engineers, who are ultimately trying to establish the best results for users
Understanding what problems machines are solving for, their current capabilities and scientists' goals
Understanding the competitive ecosystem and how companies are using machine learning to drive results
Preparing oneself for for what many industry leaders call a major shift in our society (Andrew Ng refers to AI as a "new electricity")
Understanding basic concepts that often appear within research (it's helped me with understanding certain concepts that appear within Google Brain's Research)
Growing as an individual and expanding your horizons (you might really enjoy machine learning!)
When code works and data is produced, it's a very fulfilling, empowering feeling (even if it's a very humble result)
I spent a year taking online courses, reading books, and learning about learning (...as a machine). This post is the fruit borne of that labor -- it covers 17 machine learning resources (including online courses, books, guides, conference presentations, etc.) comprising the most affordable and popular machine learning resources on the web (through the lens of a complete beginner). I've also added a summary of "If I were to start over again, how I would approach it."
This article isn't about credit or degrees. It's about regular Joes and Joannas with an interest in machine learning, and who want to spend their learning time efficiently. Most of these resources will consume over 50 hours of commitment. Ain't nobody got time for a painful waste of a work week (especially when this is probably completed during your personal time). The goal here is for you to find the resource that best suits your learning style. I genuinely hope you find this research useful, and I encourage comments on which materials prove most helpful (especially ones not included)! #HumanLearningMachineLearning
Executive summary:
Here's everything you need to know in a chart:
Machine Learning Resource
Time (hours)
Cost ($)
Year
Credibility
Code
Math
Enjoyability
Jason Maye's Machine Learning 101 slidedeck: 2 years of headbanging, so you don't have to
2
$0
'17
{ML} Recipes with Josh Gordon Playlist
2
$0
'16
Machine Learning Crash Course
15
$0
'18
OCDevel Machine Learning Guide Podcast
30
$0
'17-
Kaggle's Machine Learning Track (part 1)
6
$0
'17
Fast.ai (part 1)
70
$70*
'16
Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems
20
$25
'17
Udacity's Intro to Machine Learning (Kate/Sebastian)
60
$0
'15
Andrew Ng's Coursera Machine Learning
55
$0
'11
iPullRank Machine Learning Guide
3
$0
'17
Review Google PhD
2
$0
'17
Caltech Machine Learning on iTunes
27
$0
'12
Pattern Recognition & Machine Learning by Christopher Bishop
150
$75
'06
N/A
Machine Learning: Hands-on for Developers and Technical Professionals
15
$50
'15
Introduction to Machine Learning with Python: A Guide for Data Scientists
15
$25
'16
Udacity's Machine Learning by Georgia Tech
96
$0
'15
Machine Learning Stanford iTunes by Andrew Ng
25
$0
'08
N/A
*Free, but there is the cost of running an AWS EC2 instance (~$70 when I finished, but I did tinker a ton and made a Rick and Morty script generator, which I ran many epochs [rounds] of...)
Here's my suggested program:
1. Starting out (estimated 60 hours)
Start with shorter content targeting beginners. This will allow you to get the gist of what's going on with minimal time commitment.
Commit three hours to Jason Maye's Machine Learning 101 slidedeck: 2 years of headbanging, so you don't have to.
Commit two hours to watch Google's {ML} Recipes with Josh Gordon YouTube Playlist.
Sign up for Sam DeBrule's Machine Learnings newsletter.
Work through Google's Machine Learning Crash Course.
Start listening to OCDevel's Machine Learning Guide Podcast (skip episodes 1, 3, 16, 21, and 26) in your car, working out, and/or when using hands and eyes for other activities.
Commit two days to working through Kaggle's Machine Learning Track part 1.
2. Ready to commit (estimated 80 hours)
By this point, learners would understand their interest levels. Continue with content focused on applying relevant knowledge as fast as possible.
Commit to Fast.ai 10 hours per week, for 7 weeks. If you have a friend/mentor that can help you work through AWS setup, definitely lean on any support in installation (it's 100% the worst part of ML).
Acquire Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems, and read the first two chapters immediately. Then use this as supplemental to the Fast.ai course.
3. Broadening your horizons (estimated 115 hours)
If you've made it through the last section and are still hungry for more knowledge, move on to broadening your horizons. Read content focused on teaching the breadth of machine learning -- building an intuition for what the algorithms are trying to accomplish (whether visual or mathematically).
Start watching videos and participating in Udacity's Intro to Machine Learning (by Sebastian Thrun and Katie Malone).
Work through Andrew Ng's Coursera Machine Learning course.
Your next steps
By this point, you will already have AWS running instances, a mathematical foundation, and an overarching view of machine learning. This is your jumping-off point to determine what you want to do.
You should be able to determine your next step based on your interest, whether it's entering Kaggle competitions; doing Fast.ai part two; diving deep into the mathematics with Pattern Recognition & Machine Learning by Christopher Bishop; giving Andrew Ng's newer Deeplearning.ai course on Coursera; learning more about specific tech stacks (TensorFlow, Scikit-Learn, Keras, Pandas, Numpy, etc.); or applying machine learning to your own problems.
Why am I recommending these steps and resources?
I am not qualified to write an article on machine learning. I don't have a PhD. I took one statistics class in college, which marked the first moment I truly understood "fight or flight" reactions. And to top it off, my coding skills are lackluster (at their best, they're chunks of reverse-engineered code from Stack Overflow). Despite my many shortcomings, this piece had to be written by someone like me, an average person.
Statistically speaking, most of us are average (ah, the bell curve/Gaussian distribution always catches up to us). Since I'm not tied to any elitist sentiments, I can be real with you. Below contains a high-level summary of my reviews on all of the classes I took, along with a plan for how I would approach learning machine learning if I could start over. Click to expand each course for the full version with notes.
In-depth reviews of machine learning courses:
Starting out
Jason Maye's Machine Learning 101 slidedeck: 2 years of head-banging, so you don't have to ↓
Need to Know: A stellar high-level overview of machine learning fundamentals in an engaging and visually stimulating format.
Loved:
Very user-friendly, engaging, and playful slidedeck.
Has the potential to take some of the pain out of the process, through introducing core concepts.
Breaks up content by beginner/need-to-know (green), and intermediate/less-useful noise (specifically for individuals starting out) (blue).
Provides resources to dive deeper into machine learning.
Provides some top people to follow in machine learning.
Disliked:
That there is not more! Jason's creativity, visual-based teaching approach, and quirky sense of humor all support the absorption of the material.
Lecturer:
Jason Mayes:
Senior Creative Technologist and Research Engineer at Google
Masters in Computer Science from University of Bristols
Personal Note: He's also kind on Twitter! :)
Links:
Machine Learning 101 slide deck
Tips on Watching:
Set aside 2-4 hours to work through the deck once.
Since there is a wealth of knowledge, refer back as needed (or as a grounding source).
Identify areas of interest and explore the resources provided.
{ML} Recipes with Josh Gordon ↓
Need to Know: This mini-series YouTube-hosted playlist covers the very fundamentals of machine learning with opportunities to complete exercises.
Loved:
It is genuinely beginner-focused.
They make no assumption of any prior knowledge.
Gloss over potentially complex topics that may serve as noise.
Playlist ~2 hours
Very high-quality filming, audio, and presentation, almost to the point where it had its own aesthetic.
Covers some examples in scikit-learn and TensorFlow, which felt modern and practical.
Josh Gordon was an engaging speaker.
Disliked:
I could not get Dockers on Windows (suggested package manager). This wasn't a huge deal, since I already had my AWS setup by this point; however, a bit of a bummer since it made it impossible to follow certain steps exactly.
Issue: Every time I tried to download (over the course of two weeks), the .exe file would recursively start and keep spinning until either my memory ran out, computer crashed, or I shut my computer down. I sent this to Docker's Twitter account to no avail.
Lecturer:
Josh Gordon:
Developer Advocate for at TensorFlow at Google
Leads Machine Learning advocacy at Google
Member of the Udacity AI & Data Industry Advisory Board
Masters in Computer Science from Columbia University
Links:
Hello World - Machine Learning Recipes #1 (YouTube)
GitHub: Machine Learning Recipes with Josh Gordon
Tips on Watching:
The playlist is short (only ~1.5 hours screen time). However, it can be a bit fast-paced at times (especially if you like mimicking the examples), so set aside 3-4 hours to play around with examples and allow time for installation, pausing, and following along.
Take time to explore code labs.
Google's Machine Learning Crash Course with TensorFlow APIs ↓
Need to Know: A Google researcher-made crash course on machine learning that is interactive and offers its own built-in coding system!
Loved:
Different formats of learning: high-quality video (with ability to adjust speed, closed captioning), readings, quizzes (with explanations), visuals (including whiteboarding), interactive components/ playgrounds, code lab exercises (run directly in your browser (no setup required!))
Non-intimidating
One of my favorite quotes: "You don't need to understand the math to be able to take a look at the graphical interpretation."
Broken down into digestible sections
Introduces key terms
Disliked:
N/A
Lecturers:
Multiple Google researchers participated in this course, including:
Peter Norvig
Director of Research at Google Inc.
Previously he directed Google's core search algorithms group.
He is co-author of Artificial Intelligence: A Modern Approach
D. Sculley
Senior Staff Software Engineer at Google
KDD award-winning papers
Works on massive-scale ML systems for online advertising
Was part of a research ML paper on optimizing chocolate chip cookies
According to his personal website, he prefers to go by "D."
Cassandra Xia
Programmer, Software Engineer at Google
She has some really cool (and cute) projects based on learning statistics concepts interactively
Maya Gupta
Leads Glassbox Machine Learning R&D team at Google
Associate Professor of Electrical Engineering at the University of Washington (2003-2012)
In 2007, Gupta received the PECASE award from President George Bush for her work in classifying uncertain (e.g. random) signals
Gupta also runs Artifact Puzzles, the second-largest US maker of wooden jigsaw puzzles
Sally Goldman
Research Scientist at Google
Co-author of A Practical Guide to Data Structures and Algorithms Using Java
Numerous journals, classes taught at Washington University, and contributions to the ML community
Links:
Machine Learning Crash Course
Tips on Doing:
Actively work through playground and coding exercises
OCDevel's Machine Learning Guide Podcast ↓
Need to Know: This podcast focuses on the high-level fundamentals of machine learning, including basic intuition, algorithms, math, languages, and frameworks. It also includes references to learn more on each episode's topic.
Loved:
Great for trips (when traveling a ton, it was an easy listen).
The podcast makes machine learning fun with interesting and compelling analogies.
Tyler is a big fan of Andrew Ng's Coursera course and reviews concepts in Coursera course very well, such that both pair together nicely.
Covers the canonical resources for learning more on a particular topic.
Disliked:
Certain courses were more theory-based; all are interesting, yet impractical.
Due to limited funding the project is a bit slow to update and has less than 30 episodes.
Podcaster:
Tyler Renelle:
Machine learning engineer focused on time series and reinforcement
Background in full-stack JavaScript, 10 years web and mobile
Creator of HabitRPG, an app that treats habits as an RPG game
Links:
Machine Learning Guide podcast
Machine Learning Guide podcast (iTunes)
Tips on Listening:
Listen along your journey to help solidify understanding of topics.
Skip episodes 1, 3, 16, 21, and 26 (unless their topics interest and inspire you!).
Kaggle Machine Learning Track (Lesson 1) ↓
Need to Know: A simple code lab that covers the very basics of machine learning with scikit-learn and Panda through the application of the examples onto another set of data.
Loved:
A more active form of learning.
An engaging code lab that encourages participants to apply knowledge.
This track offers has a built-in Python notebook on Kaggle with all input files included. This removed any and all setup/installation issues.
Side note: It's a bit different than Jupyter notebook (e.g., have to click into a cell to add another cell).
Each lesson is short, which made the entire lesson go by very fast.
Disliked:
The writing in the first lesson didn't initially make it clear that one would need to apply the knowledge in the lesson to their workbook.
It wasn't a big deal, but when I started referencing files in the lesson, I had to dive into the files in my workbook to find they didn't exist, only to realize that the knowledge was supposed to be applied and not transcribed.
Lecturer:
Dan Becker:
Data Scientist at Kaggle
Undergrad in Computer Science, PhD in Econometrics
Supervised data science consultant for six Fortune 100 companies
Contributed to the Keras and Tensorflow libraries
Finished 2nd (out of 1353 teams) in $3 million Heritage Health Prize data mining competition
Speaks at deep learning workshops at events and conferences
Links:
https://www.kaggle.com/learn/machine-learning
Tips on Doing:
Read the exercises and apply to your dataset as you go.
Try lesson 2, which covers more complex/abstract topics (note: this second took a bit longer to work through).
Ready to commit
Fast.ai (part 1 of 2) ↓
Need to Know: Hands-down the most engaging and active form of learning ML. The source I would most recommend for anyone (although the training plan does help to build up to this course). This course is about learning through coding. This is the only course that I started to truly see the practical mechanics start to come together. It involves applying the most practical solutions to the most common problems (while also building an intuition for those solutions).
Loved:
Course Philosophy:
Active learning approach
"Go out into the world and understand underlying mechanics (of machine learning by doing)."
Counter-culture to the exclusivity of the machine learning field, focusing on inclusion.
"Let's do shit that matters to people as quickly as possible."
Highly pragmatic approach with tools that are currently being used (Jupyter Notebooks, scikit-learn, Keras, AWS, etc.).
Show an end-to-end process that you get to complete and play with in a development environment.
Math is involved, but is not prohibitive. Excel files helped to consolidate information/interact with information in a different way, and Jeremy spends a lot of time recapping confusing concepts.
Amazing set of learning resources that allow for all different styles of learning, including:
Video Lessons
Notes
Jupyter Notebooks
Assignments
Highly active forums
Resources on Stackoverflow
Readings/resources
Jeremy often references popular academic texts
Jeremy's TEDx talk in Brussels
Jeremy really pushes one to do extra and put in the effort by teaching interesting problems and engaging one in solving them.
It's a huge time commitment; however, it's worth it.
All of the course's profits are donated.
Disliked:
Overview covers their approach to learning (obviously I'm a fan!). If you're already drinking the Kool-aid, skip past.
I struggled through the AWS setup (13-minute video) for about five hours (however, it felt so good when it was up and running!).
Because of its practicality and concentration on solutions used today to solve popular problem types (image recognition, text generation, etc.), it lacks breadth of machine learning topics.
Lecturers:
Jeremy Howard:
Distinguished Research Scientist at the University of San Francisco
Faculty member at Singularity University
Young Global Leader with the World Economic Forum
Founder of Enlitic (the first company to apply deep learning to medicine)
Former President and Chief Scientist of the data science platform Kaggle
Rachel Thomas:
PhD in Math from Duke
One of Forbes' "20 Incredible Women Advancing AI Research"
Researcher-in-residence at the University of San Francisco Data Institute
Teaches in the Masters in Data Science program
Links:
http://course.fast.ai/start.html
http://wiki.fast.ai/index.php/Main_Page
https://github.com/fastai/courses/tree/master/deeplearning1/nbs
Tips on Doing:
Set expectations with yourself that installation is going to probably take a few hours.
Prepare to spend about ~70 hours for this course (it's worth it).
Don't forget to shut off your AWS instance.
Balance out machine learning knowledge with a course with more breadth.
Consider giving part two of the Fast.ai program a shot!
Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems ↓
Need to Know: This book is an Amazon best seller for a reason. It covers a lot of ground quickly, empowers readers to walk through a machine learning problem by chapter two, and contains practical up-to-date machine learning skills.
Loved:
Book contains an amazing introduction to machine learning that briskly provides an overarching quick view of the machine learning ecosystem.
Chapter 2 immediately walks the reader through an end-to-end machine learning problem.
Immediately afterwards, Aurélien pushes a user to attempt to apply this solution to another problem, which was very empowering.
There are review questions at the end of each chapter to ensure on has grasped the content within the chapter and to push the reader to explore more.
Once installation was completed, it was easy to follow and all code is available on GitHub.
Chapters 11-14 were very tough reading; however, they were a great reference when working through Fast.ai.
Contains some powerful analogies.
Each chapter's introductions were very useful and put everything into context. This general-to-specifics learning was very useful.
Disliked:
Installation was a common source of issues during the beginning of my journey; the text glided over this. I felt the frustration that most people experience from installation should have been addressed with more resources.
Writer:
Aurélien Géron:
Led the YouTube video classification team from 2013 to 2016
Currently a machine Learning consultant
Founder and CTO of Wifirst and Polyconseil
Published technical books (on C++, Wi-Fi, and Internet architectures)
Links:
https://www.amazon.com/_/dp/1491962291?tag=oreilly20-20
http://shop.oreilly.com/product/0636920052289.do
https://github.com/ageron/handson-ml
Tips on Using:
Get a friend with Python experience to help with installation.
Read the introductions to each chapter thoroughly, read the chapter (pay careful attention to code), review the questions at the end (highlight any in-text answer), make a copy of Aurélien's GitHub and make sure everything works on your setup, re-type the notebooks, go to Kaggle and try on other datasets.
Broadening your horizons
Udacity: Intro to Machine Learning (Kate/Sebastian) ↓
Need to Know: A course that covers a range of machine learning topics, supports building of intuition via visualization and simple examples, offers coding challenges, and a certificate (upon completion of a final project). The biggest challenge with this course is bridging the gap between the hand-holding lectures and the coding exercises.
Loved:
Focus on developing a visual intuition on what each model is trying to accomplish.
This visual learning mathematics approach is very useful.
Cover a vast variety and breadth of models and machine learning basics.
In terms of presenting the concept, there was a lot of hand-holding (which I completely appreciated!).
Many people have done this training, so their GitHub accounts can be used as reference for the mini-projects.
Katie actively notes documentation and suggests where viewers can learn more/reference material.
Disliked:
All of the conceptual hand-holding in the lessons is a stark contrast to the challenges of installation, coding exercises, and mini-projects.
This is the first course started and the limited instructions on setting up the environment and many failed attempts caused me to break down crying at least a handful of times.
The mini-projects are intimidating.
There is extra code added to support the viewers; however, it's done so with little acknowledgement as to what it's actually doing. This made learning a bit harder.
Lecturer:
Caitlin (Katie) Malone:
Director of Data Science Research and Development at Civis Analytics
Stanford PhD in Experimental Particle Physics
Intern at Udacity in summer 2014
Graduate Researcher at the SLAC National Accelerator Laboratory
https://www6.slac.stanford.edu/
Podcaster with Ben Jaffe (currently Facebook UI Engineer and a music aficionado) on a machine learning podcast Linear Digressions (100+ episodes)
Sebastian Thrun:
CEO of the Kitty Hawk Corporation
Chairman and co-founder of Udacity
One of my favorite Sebastian quotes: "It occurred to me, I could be at Google and build a self-driving car, or I can teach 10,000 students how to build self-driving cars."
Former Google VP
Founded Google X
Led development of the robotic vehicle Stanley
Professor of Computer Science at Stanford University
Formerly a professor at Carnegie Mellon University.
Links:
https://www.udacity.com/course/intro-to-machine-learning--ud120
Udacity also offers a next step, the Machine Learning Engineer Nanodegree, which will set one back about $1K.
Tips on Watching:
Get a friend to help you set up your environment.
Print mini-project instructions to check off each step.
Andrew Ng's Coursera Machine Learning Course ↓
Need to Know: The Andrew Ng Coursera course is the most referenced online machine learning course. It covers a broad set of fundamental, evergreen topics with a strong focus in building mathematical intuition behind machine learning models. Also, one can submit assignments and earn a grade for free. If you want to earn a certificate, one can subscribe or apply for financial aid.
Loved:
This course has a high level of credibility.
Introduces all necessary machine learning terminology and jargon.
Contains a very classic machine learning education approach with a high level of math focus.
Quizzes interspersed in courses and after each lesson support understanding and overall learning.
The sessions for the course are flexible, the option to switch into a different section is always available.
Disliked:
The mathematic notation was hard to process at times.
The content felt a bit dated and non-pragmatic. For example, the main concentration was MATLAB and Octave versus more modern languages and resources.
Video quality was less than average and could use a refresh.
Lecturer:
Andrew Ng:
Adjunct Professor, Stanford University (focusing on AI, Machine Learning, and Deep Learning)
Co-founder of Coursera
Former head of Baidu AI Group
Founder and previous head of Google Brain (deep learning) project
Former Director of the Stanford AI Lab
Chairman of the board of Woebot (a machine learning bot that focuses on Cognitive Behavior Therapy)
Links:
https://www.coursera.org/learn/machine-learning/
Andrew Ng recently launched a new course (August 2017) called DeepLearning.ai, a ~15 week course containing five mini-courses ($49 USD per month to continue learning after trial period of 7 days ends).
Course: https://www.coursera.org/specializations/deep-learning
Course 1: Neural Networks and Deep Learning
Course 2: Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization
Course 3: Structuring Machine Learning Projects
Course 4: Convolutional Neural Networks
Course 5: Sequence Models
Tips on Watching:
Be disciplined with setting aside timing (even if it's only 15 minutes a day) to help power through some of the more boring concepts.
Don't do this course first, because it's intimidating, requires a large time commitment, and isn't a very energizing experience.
Additional machine learning opportunities
iPullRank Machine Learning Guide ↓
Need to Know: A machine learning e-book targeted at marketers.
Loved:
Targeted at marketers and applied to organic search.
Covers a variety of machine learning topics.
Some good examples, including real-world blunders.
Gives some practical tools for non-data scientists (including: MonkeyLearn and Orange)
I found Orange to be a lot of fun. It struggled with larger datasets; however, it has a very visual interface that was more user-friendly and offers potential to show some pretty compelling stories.
Example: World Happiness Dataset by:
X-axis: Happiness Score
Y-axis: Economy
Color: Health
Disliked:
Potential to break up content more with relevant imagery -- the content was very dense.
Writers:
iPullRank Team (including Mike King):
Mike King has a few slide decks on the basics of machine learnings and AI
iPullRank has a few data scientists on staff
Links:
http://ipullrank.com/machine-learning-guide/
Tips on Reading:
Read chapters 1-6 and the rest depending upon personal interest.
Review Google PhD ↓
Need to Know: A two-hour presentation from Google's 2017 IO conference that walks through getting 99% accuracy on the MNIST dataset (a famous dataset containing a bunch of handwritten numbers, which the machine must learn to identify the numbers).
Loved:
This talk struck me as very modern, covering the cutting edge.
Found this to be very complementary to Fast.ai, as it covered similar topics (e.g. ReLu, CNNs, RNNs, etc.)
Amazing visuals that help to put everything into context.
Disliked:
The presentation is only a short conference solution and not a comprehensive view of machine learning.
Also, a passive form of learning.
Presenter:
Martin Görner:
Developer Relations, Google (since 2011)
Started Mobipocket, a startup that later became the software part of the Amazon Kindle and its mobile variants
Links:
Part 1 - https://www.youtube.com/watch?v=u4alGiomYP4
Part 2 - https://www.youtube.com/watch?v=fTUwdXUFfI8
Tips on Watching:
Google any concepts you're unfamiliar with.
Take your time with this one; 2 hours of screen time doesn't count all of the Googling and processing time for this one.
Caltech Machine Learning iTunes ↓
Need to Know: If math is your thing, this course does a stellar job of building the mathematic intuition behind many machine learning models. Dr. Abu-Mostafa is a raconteur, includes useful visualizations, relevant real-world examples, and compelling analogies.
Loved:
First and foremost, this is a real Caltech course, meaning it's not a watered-down version and contains fundamental concepts that are vital to understanding the mechanics of machine learning.
On iTunes, audio downloads are available, which can be useful for on-the-go learning.
Dr. Abu-Mostafa is a skilled speaker, making the 27 hours spent listening much easier!
Dr. Abu-Mostafa offers up some strong real-world examples and analogies which makes the content more relatable.
As an example, he asks students: "Why do I give you practice exams and not just give you the final exam?" as an illustration of why a testing set is useful. If he were to just give students the final, they would just memorize the answers (i.e., they would overfit to the data) and not genuinely learn the material. The final is a test to show how much students learn.
The last 1/2 hour of the class is always a Q&A, where students can ask questions. Their questions were useful to understanding the topic more in-depth.
The video and audio quality was strong throughout. There were a few times when I couldn't understand a question in the Q&A, but overall very strong.
This course is designed to build mathematical intuition of what's going on under the hood of specific machine learning models.
Caution: Dr. Abu-Mostafa uses mathematical notation, but it's different from Andrew Ng's (e.g., theta = w).
The final lecture was the most useful, as it pulled a lot of the conceptual puzzle pieces together. The course on neural networks was a close second!
Disliked:
Although it contains mostly evergreen content, being released in 2012, it could use a refresh.
Very passive form of learning, as it wasn't immediately actionable.
Lecturer:
Dr. Yaser S. Abu-Mostafa:
Professor of Electrical Engineering and Computer Science at the California Institute of Technology
Chairman of Machine Learning Consultants LLC
Serves on a number of scientific advisory boards
Has served as a technical consultant on machine learning for several companies (including Citibank).
Multiple articles in Scientific American
Links:
https://work.caltech.edu/telecourse.html
https://itunes.apple.com/us/course/machine-learning/id515364596
Tips on Watching:
Consider listening to the last lesson first, as it pulls together the course overall conceptually. The map of the course, below, was particularly useful to organizing the information taught in the courses.
Image source: http://work.caltech.edu/slides/slides18.pdf
"Pattern Recognition & Machine Learning" by Christopher Bishop ↓
Need to Know: This is a very popular college-level machine learning textbook. I've heard it likened to a bible for machine learning. However, after spending a month trying to tackle the first few chapters, I gave up. It was too much math and pre-requisites to tackle (even with a multitude of Google sessions).
Loved:
The text of choice for many major universities, so if you can make it through this text and understand all of the concepts, you're probably in a very good position.
I appreciated the history aside sections, where Bishop talked about influential people and their career accomplishments in statistics and machine learning.
Despite being a highly mathematically text, the textbook actually has some pretty visually intuitive imagery.
Disliked:
I couldn't make it through the text, which was a bit frustrating. The statistics and mathematical notation (which is probably very benign for a student in this topic) were too much for me.
The sunk cost was pretty high here (~$75).
Writer:
Christopher Bishop:
Laboratory Director at Microsoft Research Cambridge
Professor of Computer Science at the University of Edinburgh
Fellow of Darwin College, Cambridge
PhD in Theoretical Physics from the University of Edinburgh
Links:
https://www.amazon.com/Pattern-Recognition-Learning-Information-Statistics/dp/0387310738/ref=sr_1_2?ie=UTF8&qid=1516839475&sr=8-2&keywords=Pattern+Recognition+%26+Machine+Learning
Tips on Reading:
Don't start your machine learning journey with this book.
Get a friend in statistics to walk you through anything complicated (my plan is to get a mentor in statistics).
Consider taking a (free) online statistics course (Khan Academy and Udacity both have some great content on statistics, calculus, math, and data analysis).
Machine Learning: Hands-on for Developers and Technical Professionals ↓
Need to Know: A fun, non-intimidating end-to-end launching pad/whistle stop for machine learning in action.
Loved:
Talks about practical issues that many other sources didn't really address (e.g. data-cleansing).
Covered the basics of machine learning in a non-intimidating way.
Offers abridged, consolidated versions of the content.
Added fun anecdotes that makes it easier to read.
Overall the writer has a great sense of humor.
Writer talks to the reader as if they're a real human being (i.e., doesn't expect you to go out and do proofs; acknowledges the challenge of certain concepts).
Covers a wide variety of topics.
Because it was well-written, I flew through the book (even though it's about ~300 pages).
Disliked:
N/A
Writer:
Jason Bell:
Technical architect, lecturer, and startup consultant
Data Engineer at MastodonC
Former section editor for Java Developer's Journal
Former writer on IBM DeveloperWorks
Links:
https://www.amazon.com/Machine-Learning-Hands-Developers-Professionals/dp/1118889061
https://www.wiley.com/en-us/Machine+Learning%3A+Hands+On+for+Developers+and+Technical+Professionals-p-9781118889060
Jason's Blog: https://dataissexy.wordpress.com/
Tips on Reading:
Download and explore Weka's interface beforehand.
Give some of the exercises a shot.
Introduction to Machine Learning with Python: A Guide for Data Scientists ↓
Need to Know: This was a was a well-written piece on machine learning, making it a quick read.
Loved:
Quick, smooth read.
Easy-to-follow code examples.
The first few chapters served as a stellar introduction to the basics of machine learning.
Contain subtle jokes that add a bit of fun.
Tip to use the Python package manager Anaconda with Jupyter Notebooks was helpful.
Disliked:
Once again, installation was a challenge.
The "mglearn" utility library threw me for a loop. I had to reread the first few chapters before I figured out it was support for the book.
Although I liked the book, I didn't love it. Overall it just missed the "empowering" mark.
Writers:
Andreas C. Müller:
PhD in Computer Science
Lecturer at the Data Science Institute at Columbia University
Worked at the NYU Center for Data Science on open source and open science
Former Machine Learning Scientist at Amazon
Speaks often on Machine Learning and scikit-learn (a popular machine learning library)
And he makes some pretty incredibly useful graphics, such as this scikit-learn cheat sheet:
Image source: http://peekaboo-vision.blogspot.com/2013/01/machin...
Sarah Guido:
Former senior data scientist at Mashable
Lead data scientist at Bitly
2018 SciPy Conference Data Science track co-chair
Links:
https://www.amazon.com/Introduction-Machine-Learning-Python-Scientists/dp/1449369413/ref=sr_1_7?s=books&ie=UTF8&qid=1516734322&sr=1-7&keywords=python+machine+learning
http://shop.oreilly.com/product/0636920030515.do
Tips on Reading:
Type out code examples.
Beware of the "mglearn" utility library.
Udacity: Machine Learning by Georgia Tech ↓
Need to Know: A mix between an online learning experience and a university machine learning teaching approach. The lecturers are fun, but the course still fell a bit short in terms of active learning.
Loved:
This class is offered as CS7641 at Georgia Tech, where it is a part of the Online Masters Degree. Although taking this course here will not earn credit towards the OMS degree, it's still a non-watered-down college teaching philosophy approach.
Covers a wide variety of topics, many of which reminded me of the Caltech course (including: VC Dimension versus Bayesian, Occam's razor, etc.)
Discusses Markov Decision Chains, which is something that didn't really come up in many other introductory machine learning course, but they are referenced within Google patents.
The lecturers have a great dynamic, are wicked smart, and displayed a great sense of (nerd) humor, which make the topics less intimidating.
The course has quizzes, which give the course a slight amount of interaction.
Disliked:
Some videos were very long, which made the content a bit harder to digest.
The course overall was very time consuming.
Despite the quizzes, the course was a very passive form of learning with no assignments and little coding.
Many videos started with a bunch of content already written out. Having the content written out was probably a big time-saver, but it was also a bit jarring for a viewer to see so much information all at once, while also trying to listen.
It's vital to pay very close attention to notation, which compounds in complexity quickly.
Tablet version didn't function flawlessly: some was missing content (which I had to mark down and review on a desktop), the app would crash randomly on the tablet, and sometimes the audio wouldn't start.
There were no subtitles available on tablet, which I found not only to be a major accessibility blunder, but also made it harder for me to process (since I'm not an audio learner).
Lecturer:
Michael Littman:
Professor of Computer Science at Brown University.
Was granted a patent for one of the earliest systems for Cross-language information retrieval
Perhaps the most interesting man in the world:
Been in two TEDx talks
How I Learned to Stop Worrying and Be Realistic About AI
A Cooperative Path to Artificial Intelligence
During his time at Duke, he worked on an automated crossword solver (PROVERB)
Has a Family Quartet
He has appeared in a TurboTax commercial
Charles Isbell:
Professor and Executive Associate Dean at School of Interactive Computing at Georgia Tech
Focus on statistical machine learning and "interactive" artificial intelligence.
Links:
https://www.udacity.com/course/machine-learning--ud262
Tips on Watching:
Pick specific topics of interest and focusing on those lessons.
Andrew Ng's Stanford's Machine Learning iTunes ↓
Need to Know: A non-watered-down Stanford course. It's outdated (filmed in 2008), video/audio are a bit poor, and most links online now point towards the Coursera course. Although the idea of watching a Stanford course was energizing for the first few courses, it became dreadfully boring. I made it to course six before calling it.
Loved:
Designed for students, so you know you're not missing out on anything.
This course provides a deeper study into the mathematical and theoretical foundation behind machine learning to the point that the students could create their own machine learning algorithms. This isn't necessarily very practical for the everyday machine learning user.
Has some powerful real-world examples (although they're outdated).
There is something about the kinesthetic nature of watching someone write information out. The blackboard writing helped me to process certain ideas.
Disliked:
Video and audio quality were pain to watch.
Many questions asked by students were hard to hear.
On-screen visuals range from hard to impossible to see.
Found myself counting minutes.
Dr. Ng mentions TA classes, supplementary learning, but these are not available online.
Sometimes the video showed students, which I felt was invasive.
Lecturer:
Andrew Ng (see above)
Links:
https://itunes.apple.com/us/course/machine-learning/id495053006
https://www.youtube.com/watch?v=UzxYlbK2c7E
Tips on Watching:
Only watch if you're looking to gain a deeper understanding of the math presented in the Coursera course.
Skip the first half of the first lecture, since it's mostly class logistics.
Additional Resources
Fast.ai (part 2) - free access to materials, cost for AWS EC2 instance
Deeplearning.ai - $50/month
Udacity Machine Learning Engineer Nanodegree - $1K
https://machinelearningmastery.com/
Motivations and inspiration
If you're wondering why I spent a year doing this, then I'm with you. I'm genuinely not sure why I set my sights on this project, much less why I followed through with it. I saw Mike King give a session on Machine Learning. I was caught off guard, since I knew nothing on the topic. It gave me a pesky, insatiable curiosity itch. It started with one course and then spiraled out of control. Eventually it transformed into an idea: a review guide on the most affordable and popular machine learning resources on the web (through the lens of a complete beginner). Hopefully you found it useful, or at least somewhat interesting. Be sure to share your thoughts or questions in the comments!
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
https://ift.tt/2q13Myy xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ A Machine Learning Guide for Average Humans https://ift.tt/2rFyAUY Bạn có thể xem thêm địa chỉ mua tai nghe không dây tại đây https://ift.tt/2mb4VST
0 notes
Text
Machine Learning
https://youtube.com/playlist?list=PLCmAM0wpuQ4910msQ5Bs8txh2LqvWLV4R
Python Tkinter Library
https://youtube.com/playlist?list=PLCmAM0wpuQ49Mgfe1wz8tCQRh3NMWtHhq
Java Full course
https://youtube.com/playlist?list=PLCmAM0wpuQ48HV8ph_oKf1haNpntsFGAr
Pandas Full cours
https://youtube.com/playlist?list=PLCmAM0wpuQ4-vdg-JtGgRm0rgMC1QnvH8
WordPress full course
https://youtube.com/playlist?list=PLCmAM0wpuQ49HpucvtT7dMe7L2X2BBsAO
Numpy
https://youtube.com/playlist?list=PLCmAM0wpuQ4_82zMt05FNLMrWaGLLP-4H
String function in c program
https://youtube.com/playlist?list=PLCmAM0wpuQ4-4iQsIovYPxY-lDc714aln
Matplotlib data visualization
https://youtube.com/playlist?list=PLCmAM0wpuQ49cqfUZRBP-nOQBeCqLKxZ5
Python
https://youtube.com/playlist?list=PLCmAM0wpuQ484UV_lo5l_F0IZLdk1H4z4
Ethical hacking
https://youtube.com/playlist?list=PLCmAM0wpuQ48Oet9rkIItDkDjhzpq8fLD
Subscribe my youtube channel and press bell icon to get instant notification when we will upload video
#

0 notes
Text
A Machine Learning Guide for Average Humans
Posted by alexis-sanders
//<![CDATA[ (function($) { // code using $ as alias to jQuery $(function() { // Hide the hypotext content. $('.hypotext-content').hide(); // When a hypotext link is clicked. $('a.hypotext.closed').click(function (e) { // custom handling here e.preventDefault(); // Create the class reference from the rel value. var id = '.' + $(this).attr('rel'); // If the content is hidden, show it now. if ( $(id).css('display') == 'none' ) { $(id).show('slow'); if (jQuery.ui) { // UI loaded $(id).effect("highlight", {}, 1000); } } // If the content is shown, hide it now. else { $(id).hide('slow'); } }); // If we have a hash value in the url. if (window.location.hash) { // If the anchor is within a hypotext block, expand it, by clicking the // relevant link. console.log(window.location.hash); var anchor = $(window.location.hash); var hypotextLink = $('#' + anchor.parents('.hypotext-content').attr('rel')); console.log(hypotextLink); hypotextLink.click(); // Wait until the content has expanded before jumping to anchor. //$.delay(1000); setTimeout(function(){ scrollToAnchor(window.location.hash); }, 1000); } }); function scrollToAnchor(id) { var anchor = $(id); $('html,body').animate({scrollTop: anchor.offset().top},'slow'); } })(jQuery); //]]>
Machine learning (ML) has grown consistently in worldwide prevalence. Its implications have stretched from small, seemingly inconsequential victories to groundbreaking discoveries. The SEO community is no exception. An understanding and intuition of machine learning can support our understanding of the challenges and solutions Google's engineers are facing, while also opening our minds to ML's broader implications.
The advantages of gaining an general understanding of machine learning include:
Gaining empathy for engineers, who are ultimately trying to establish the best results for users
Understanding what problems machines are solving for, their current capabilities and scientists' goals
Understanding the competitive ecosystem and how companies are using machine learning to drive results
Preparing oneself for for what many industry leaders call a major shift in our society (Andrew Ng refers to AI as a "new electricity")
Understanding basic concepts that often appear within research (it's helped me with understanding certain concepts that appear within Google Brain's Research)
Growing as an individual and expanding your horizons (you might really enjoy machine learning!)
When code works and data is produced, it's a very fulfilling, empowering feeling (even if it's a very humble result)
I spent a year taking online courses, reading books, and learning about learning (...as a machine). This post is the fruit borne of that labor -- it covers 17 machine learning resources (including online courses, books, guides, conference presentations, etc.) comprising the most affordable and popular machine learning resources on the web (through the lens of a complete beginner). I've also added a summary of "If I were to start over again, how I would approach it."
This article isn't about credit or degrees. It's about regular Joes and Joannas with an interest in machine learning, and who want to spend their learning time efficiently. Most of these resources will consume over 50 hours of commitment. Ain't nobody got time for a painful waste of a work week (especially when this is probably completed during your personal time). The goal here is for you to find the resource that best suits your learning style. I genuinely hope you find this research useful, and I encourage comments on which materials prove most helpful (especially ones not included)! #HumanLearningMachineLearning
Executive summary:
Here's everything you need to know in a chart:
Machine Learning Resource
Time (hours)
Cost ($)
Year
Credibility
Code
Math
Enjoyability
Jason Maye's Machine Learning 101 slidedeck: 2 years of headbanging, so you don't have to
2
$0
'17
{ML} Recipes with Josh Gordon Playlist
2
$0
'16
Machine Learning Crash Course
15
$0
'18
OCDevel Machine Learning Guide Podcast
30
$0
'17-
Kaggle's Machine Learning Track (part 1)
6
$0
'17
Fast.ai (part 1)
70
$70*
'16
Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems
20
$25
'17
Udacity's Intro to Machine Learning (Kate/Sebastian)
60
$0
'15
Andrew Ng's Coursera Machine Learning
55
$0
'11
iPullRank Machine Learning Guide
3
$0
'17
Review Google PhD
2
$0
'17
Caltech Machine Learning on iTunes
27
$0
'12
Pattern Recognition & Machine Learning by Christopher Bishop
150
$75
'06
N/A
Machine Learning: Hands-on for Developers and Technical Professionals
15
$50
'15
Introduction to Machine Learning with Python: A Guide for Data Scientists
15
$25
'16
Udacity's Machine Learning by Georgia Tech
96
$0
'15
Machine Learning Stanford iTunes by Andrew Ng
25
$0
'08
N/A
*Free, but there is the cost of running an AWS EC2 instance (~$70 when I finished, but I did tinker a ton and made a Rick and Morty script generator, which I ran many epochs [rounds] of...)
Here's my suggested program:
1. Starting out (estimated 60 hours)
Start with shorter content targeting beginners. This will allow you to get the gist of what's going on with minimal time commitment.
Commit three hours to Jason Maye's Machine Learning 101 slidedeck: 2 years of headbanging, so you don't have to.
Commit two hours to watch Google's {ML} Recipes with Josh Gordon YouTube Playlist.
Sign up for Sam DeBrule's Machine Learnings newsletter.
Work through Google's Machine Learning Crash Course.
Start listening to OCDevel's Machine Learning Guide Podcast (skip episodes 1, 3, 16, 21, and 26) in your car, working out, and/or when using hands and eyes for other activities.
Commit two days to working through Kaggle's Machine Learning Track part 1.
2. Ready to commit (estimated 80 hours)
By this point, learners would understand their interest levels. Continue with content focused on applying relevant knowledge as fast as possible.
Commit to Fast.ai 10 hours per week, for 7 weeks. If you have a friend/mentor that can help you work through AWS setup, definitely lean on any support in installation (it's 100% the worst part of ML).
Acquire Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems, and read the first two chapters immediately. Then use this as supplemental to the Fast.ai course.
3. Broadening your horizons (estimated 115 hours)
If you've made it through the last section and are still hungry for more knowledge, move on to broadening your horizons. Read content focused on teaching the breadth of machine learning -- building an intuition for what the algorithms are trying to accomplish (whether visual or mathematically).
Start watching videos and participating in Udacity's Intro to Machine Learning (by Sebastian Thrun and Katie Malone).
Work through Andrew Ng's Coursera Machine Learning course.
Your next steps
By this point, you will already have AWS running instances, a mathematical foundation, and an overarching view of machine learning. This is your jumping-off point to determine what you want to do.
You should be able to determine your next step based on your interest, whether it's entering Kaggle competitions; doing Fast.ai part two; diving deep into the mathematics with Pattern Recognition & Machine Learning by Christopher Bishop; giving Andrew Ng's newer Deeplearning.ai course on Coursera; learning more about specific tech stacks (TensorFlow, Scikit-Learn, Keras, Pandas, Numpy, etc.); or applying machine learning to your own problems.
Why am I recommending these steps and resources?
I am not qualified to write an article on machine learning. I don't have a PhD. I took one statistics class in college, which marked the first moment I truly understood "fight or flight" reactions. And to top it off, my coding skills are lackluster (at their best, they're chunks of reverse-engineered code from Stack Overflow). Despite my many shortcomings, this piece had to be written by someone like me, an average person.
Statistically speaking, most of us are average (ah, the bell curve/Gaussian distribution always catches up to us). Since I'm not tied to any elitist sentiments, I can be real with you. Below contains a high-level summary of my reviews on all of the classes I took, along with a plan for how I would approach learning machine learning if I could start over. Click to expand each course for the full version with notes.
In-depth reviews of machine learning courses:
Starting out
Jason Maye's Machine Learning 101 slidedeck: 2 years of head-banging, so you don't have to ↓
Need to Know: A stellar high-level overview of machine learning fundamentals in an engaging and visually stimulating format.
Loved:
Very user-friendly, engaging, and playful slidedeck.
Has the potential to take some of the pain out of the process, through introducing core concepts.
Breaks up content by beginner/need-to-know (green), and intermediate/less-useful noise (specifically for individuals starting out) (blue).
Provides resources to dive deeper into machine learning.
Provides some top people to follow in machine learning.
Disliked:
That there is not more! Jason's creativity, visual-based teaching approach, and quirky sense of humor all support the absorption of the material.
Lecturer:
Jason Mayes:
Senior Creative Technologist and Research Engineer at Google
Masters in Computer Science from University of Bristols
Personal Note: He's also kind on Twitter! :)
Links:
Machine Learning 101 slide deck
Tips on Watching:
Set aside 2-4 hours to work through the deck once.
Since there is a wealth of knowledge, refer back as needed (or as a grounding source).
Identify areas of interest and explore the resources provided.
{ML} Recipes with Josh Gordon ↓
Need to Know: This mini-series YouTube-hosted playlist covers the very fundamentals of machine learning with opportunities to complete exercises.
Loved:
It is genuinely beginner-focused.
They make no assumption of any prior knowledge.
Gloss over potentially complex topics that may serve as noise.
Playlist ~2 hours
Very high-quality filming, audio, and presentation, almost to the point where it had its own aesthetic.
Covers some examples in scikit-learn and TensorFlow, which felt modern and practical.
Josh Gordon was an engaging speaker.
Disliked:
I could not get Dockers on Windows (suggested package manager). This wasn't a huge deal, since I already had my AWS setup by this point; however, a bit of a bummer since it made it impossible to follow certain steps exactly.
Issue: Every time I tried to download (over the course of two weeks), the .exe file would recursively start and keep spinning until either my memory ran out, computer crashed, or I shut my computer down. I sent this to Docker's Twitter account to no avail.
Lecturer:
Josh Gordon:
Developer Advocate for at TensorFlow at Google
Leads Machine Learning advocacy at Google
Member of the Udacity AI & Data Industry Advisory Board
Masters in Computer Science from Columbia University
Links:
Hello World - Machine Learning Recipes #1 (YouTube)
GitHub: Machine Learning Recipes with Josh Gordon
Tips on Watching:
The playlist is short (only ~1.5 hours screen time). However, it can be a bit fast-paced at times (especially if you like mimicking the examples), so set aside 3-4 hours to play around with examples and allow time for installation, pausing, and following along.
Take time to explore code labs.
Google's Machine Learning Crash Course with TensorFlow APIs ↓
Need to Know: A Google researcher-made crash course on machine learning that is interactive and offers its own built-in coding system!
Loved:
Different formats of learning: high-quality video (with ability to adjust speed, closed captioning), readings, quizzes (with explanations), visuals (including whiteboarding), interactive components/ playgrounds, code lab exercises (run directly in your browser (no setup required!))
Non-intimidating
One of my favorite quotes: "You don't need to understand the math to be able to take a look at the graphical interpretation."
Broken down into digestible sections
Introduces key terms
Disliked:
N/A
Lecturers:
Multiple Google researchers participated in this course, including:
Peter Norvig
Director of Research at Google Inc.
Previously he directed Google's core search algorithms group.
He is co-author of Artificial Intelligence: A Modern Approach
D. Sculley
Senior Staff Software Engineer at Google
KDD award-winning papers
Works on massive-scale ML systems for online advertising
Was part of a research ML paper on optimizing chocolate chip cookies
According to his personal website, he prefers to go by "D."
Cassandra Xia
Programmer, Software Engineer at Google
She has some really cool (and cute) projects based on learning statistics concepts interactively
Maya Gupta
Leads Glassbox Machine Learning R&D team at Google
Associate Professor of Electrical Engineering at the University of Washington (2003-2012)
In 2007, Gupta received the PECASE award from President George Bush for her work in classifying uncertain (e.g. random) signals
Gupta also runs Artifact Puzzles, the second-largest US maker of wooden jigsaw puzzles
Sally Goldman
Research Scientist at Google
Co-author of A Practical Guide to Data Structures and Algorithms Using Java
Numerous journals, classes taught at Washington University, and contributions to the ML community
Links:
Machine Learning Crash Course
Tips on Doing:
Actively work through playground and coding exercises
OCDevel's Machine Learning Guide Podcast ↓
Need to Know: This podcast focuses on the high-level fundamentals of machine learning, including basic intuition, algorithms, math, languages, and frameworks. It also includes references to learn more on each episode's topic.
Loved:
Great for trips (when traveling a ton, it was an easy listen).
The podcast makes machine learning fun with interesting and compelling analogies.
Tyler is a big fan of Andrew Ng's Coursera course and reviews concepts in Coursera course very well, such that both pair together nicely.
Covers the canonical resources for learning more on a particular topic.
Disliked:
Certain courses were more theory-based; all are interesting, yet impractical.
Due to limited funding the project is a bit slow to update and has less than 30 episodes.
Podcaster:
Tyler Renelle:
Machine learning engineer focused on time series and reinforcement
Background in full-stack JavaScript, 10 years web and mobile
Creator of HabitRPG, an app that treats habits as an RPG game
Links:
Machine Learning Guide podcast
Machine Learning Guide podcast (iTunes)
Tips on Listening:
Listen along your journey to help solidify understanding of topics.
Skip episodes 1, 3, 16, 21, and 26 (unless their topics interest and inspire you!).
Kaggle Machine Learning Track (Lesson 1) ↓
Need to Know: A simple code lab that covers the very basics of machine learning with scikit-learn and Panda through the application of the examples onto another set of data.
Loved:
A more active form of learning.
An engaging code lab that encourages participants to apply knowledge.
This track offers has a built-in Python notebook on Kaggle with all input files included. This removed any and all setup/installation issues.
Side note: It's a bit different than Jupyter notebook (e.g., have to click into a cell to add another cell).
Each lesson is short, which made the entire lesson go by very fast.
Disliked:
The writing in the first lesson didn't initially make it clear that one would need to apply the knowledge in the lesson to their workbook.
It wasn't a big deal, but when I started referencing files in the lesson, I had to dive into the files in my workbook to find they didn't exist, only to realize that the knowledge was supposed to be applied and not transcribed.
Lecturer:
Dan Becker:
Data Scientist at Kaggle
Undergrad in Computer Science, PhD in Econometrics
Supervised data science consultant for six Fortune 100 companies
Contributed to the Keras and Tensorflow libraries
Finished 2nd (out of 1353 teams) in $3 million Heritage Health Prize data mining competition
Speaks at deep learning workshops at events and conferences
Links:
https://www.kaggle.com/learn/machine-learning
Tips on Doing:
Read the exercises and apply to your dataset as you go.
Try lesson 2, which covers more complex/abstract topics (note: this second took a bit longer to work through).
Ready to commit
Fast.ai (part 1 of 2) ↓
Need to Know: Hands-down the most engaging and active form of learning ML. The source I would most recommend for anyone (although the training plan does help to build up to this course). This course is about learning through coding. This is the only course that I started to truly see the practical mechanics start to come together. It involves applying the most practical solutions to the most common problems (while also building an intuition for those solutions).
Loved:
Course Philosophy:
Active learning approach
"Go out into the world and understand underlying mechanics (of machine learning by doing)."
Counter-culture to the exclusivity of the machine learning field, focusing on inclusion.
"Let's do shit that matters to people as quickly as possible."
Highly pragmatic approach with tools that are currently being used (Jupyter Notebooks, scikit-learn, Keras, AWS, etc.).
Show an end-to-end process that you get to complete and play with in a development environment.
Math is involved, but is not prohibitive. Excel files helped to consolidate information/interact with information in a different way, and Jeremy spends a lot of time recapping confusing concepts.
Amazing set of learning resources that allow for all different styles of learning, including:
Video Lessons
Notes
Jupyter Notebooks
Assignments
Highly active forums
Resources on Stackoverflow
Readings/resources
Jeremy often references popular academic texts
Jeremy's TEDx talk in Brussels
Jeremy really pushes one to do extra and put in the effort by teaching interesting problems and engaging one in solving them.
It's a huge time commitment; however, it's worth it.
All of the course's profits are donated.
Disliked:
Overview covers their approach to learning (obviously I'm a fan!). If you're already drinking the Kool-aid, skip past.
I struggled through the AWS setup (13-minute video) for about five hours (however, it felt so good when it was up and running!).
Because of its practicality and concentration on solutions used today to solve popular problem types (image recognition, text generation, etc.), it lacks breadth of machine learning topics.
Lecturers:
Jeremy Howard:
Distinguished Research Scientist at the University of San Francisco
Faculty member at Singularity University
Young Global Leader with the World Economic Forum
Founder of Enlitic (the first company to apply deep learning to medicine)
Former President and Chief Scientist of the data science platform Kaggle
Rachel Thomas:
PhD in Math from Duke
One of Forbes' "20 Incredible Women Advancing AI Research"
Researcher-in-residence at the University of San Francisco Data Institute
Teaches in the Masters in Data Science program
Links:
http://course.fast.ai/start.html
http://wiki.fast.ai/index.php/Main_Page
https://github.com/fastai/courses/tree/master/deeplearning1/nbs
Tips on Doing:
Set expectations with yourself that installation is going to probably take a few hours.
Prepare to spend about ~70 hours for this course (it's worth it).
Don't forget to shut off your AWS instance.
Balance out machine learning knowledge with a course with more breadth.
Consider giving part two of the Fast.ai program a shot!
Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems ↓
Need to Know: This book is an Amazon best seller for a reason. It covers a lot of ground quickly, empowers readers to walk through a machine learning problem by chapter two, and contains practical up-to-date machine learning skills.
Loved:
Book contains an amazing introduction to machine learning that briskly provides an overarching quick view of the machine learning ecosystem.
Chapter 2 immediately walks the reader through an end-to-end machine learning problem.
Immediately afterwards, Aurélien pushes a user to attempt to apply this solution to another problem, which was very empowering.
There are review questions at the end of each chapter to ensure on has grasped the content within the chapter and to push the reader to explore more.
Once installation was completed, it was easy to follow and all code is available on GitHub.
Chapters 11-14 were very tough reading; however, they were a great reference when working through Fast.ai.
Contains some powerful analogies.
Each chapter's introductions were very useful and put everything into context. This general-to-specifics learning was very useful.
Disliked:
Installation was a common source of issues during the beginning of my journey; the text glided over this. I felt the frustration that most people experience from installation should have been addressed with more resources.
Writer:
Aurélien Géron:
Led the YouTube video classification team from 2013 to 2016
Currently a machine Learning consultant
Founder and CTO of Wifirst and Polyconseil
Published technical books (on C++, Wi-Fi, and Internet architectures)
Links:
https://www.amazon.com/_/dp/1491962291?tag=oreilly20-20
http://shop.oreilly.com/product/0636920052289.do
https://github.com/ageron/handson-ml
Tips on Using:
Get a friend with Python experience to help with installation.
Read the introductions to each chapter thoroughly, read the chapter (pay careful attention to code), review the questions at the end (highlight any in-text answer), make a copy of Aurélien's GitHub and make sure everything works on your setup, re-type the notebooks, go to Kaggle and try on other datasets.
Broadening your horizons
Udacity: Intro to Machine Learning (Kate/Sebastian) ↓
Need to Know: A course that covers a range of machine learning topics, supports building of intuition via visualization and simple examples, offers coding challenges, and a certificate (upon completion of a final project). The biggest challenge with this course is bridging the gap between the hand-holding lectures and the coding exercises.
Loved:
Focus on developing a visual intuition on what each model is trying to accomplish.
This visual learning mathematics approach is very useful.
Cover a vast variety and breadth of models and machine learning basics.
In terms of presenting the concept, there was a lot of hand-holding (which I completely appreciated!).
Many people have done this training, so their GitHub accounts can be used as reference for the mini-projects.
Katie actively notes documentation and suggests where viewers can learn more/reference material.
Disliked:
All of the conceptual hand-holding in the lessons is a stark contrast to the challenges of installation, coding exercises, and mini-projects.
This is the first course started and the limited instructions on setting up the environment and many failed attempts caused me to break down crying at least a handful of times.
The mini-projects are intimidating.
There is extra code added to support the viewers; however, it's done so with little acknowledgement as to what it's actually doing. This made learning a bit harder.
Lecturer:
Caitlin (Katie) Malone:
Director of Data Science Research and Development at Civis Analytics
Stanford PhD in Experimental Particle Physics
Intern at Udacity in summer 2014
Graduate Researcher at the SLAC National Accelerator Laboratory
https://www6.slac.stanford.edu/
Podcaster with Ben Jaffe (currently Facebook UI Engineer and a music aficionado) on a machine learning podcast Linear Digressions (100+ episodes)
Sebastian Thrun:
CEO of the Kitty Hawk Corporation
Chairman and co-founder of Udacity
One of my favorite Sebastian quotes: "It occurred to me, I could be at Google and build a self-driving car, or I can teach 10,000 students how to build self-driving cars."
Former Google VP
Founded Google X
Led development of the robotic vehicle Stanley
Professor of Computer Science at Stanford University
Formerly a professor at Carnegie Mellon University.
Links:
https://www.udacity.com/course/intro-to-machine-learning--ud120
Udacity also offers a next step, the Machine Learning Engineer Nanodegree, which will set one back about $1K.
Tips on Watching:
Get a friend to help you set up your environment.
Print mini-project instructions to check off each step.
Andrew Ng's Coursera Machine Learning Course ↓
Need to Know: The Andrew Ng Coursera course is the most referenced online machine learning course. It covers a broad set of fundamental, evergreen topics with a strong focus in building mathematical intuition behind machine learning models. Also, one can submit assignments and earn a grade for free. If you want to earn a certificate, one can subscribe or apply for financial aid.
Loved:
This course has a high level of credibility.
Introduces all necessary machine learning terminology and jargon.
Contains a very classic machine learning education approach with a high level of math focus.
Quizzes interspersed in courses and after each lesson support understanding and overall learning.
The sessions for the course are flexible, the option to switch into a different section is always available.
Disliked:
The mathematic notation was hard to process at times.
The content felt a bit dated and non-pragmatic. For example, the main concentration was MATLAB and Octave versus more modern languages and resources.
Video quality was less than average and could use a refresh.
Lecturer:
Andrew Ng:
Adjunct Professor, Stanford University (focusing on AI, Machine Learning, and Deep Learning)
Co-founder of Coursera
Former head of Baidu AI Group
Founder and previous head of Google Brain (deep learning) project
Former Director of the Stanford AI Lab
Chairman of the board of Woebot (a machine learning bot that focuses on Cognitive Behavior Therapy)
Links:
https://www.coursera.org/learn/machine-learning/
Andrew Ng recently launched a new course (August 2017) called DeepLearning.ai, a ~15 week course containing five mini-courses ($49 USD per month to continue learning after trial period of 7 days ends).
Course: https://www.coursera.org/specializations/deep-learning
Course 1: Neural Networks and Deep Learning
Course 2: Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization
Course 3: Structuring Machine Learning Projects
Course 4: Convolutional Neural Networks
Course 5: Sequence Models
Tips on Watching:
Be disciplined with setting aside timing (even if it's only 15 minutes a day) to help power through some of the more boring concepts.
Don't do this course first, because it's intimidating, requires a large time commitment, and isn't a very energizing experience.
Additional machine learning opportunities
iPullRank Machine Learning Guide ↓
Need to Know: A machine learning e-book targeted at marketers.
Loved:
Targeted at marketers and applied to organic search.
Covers a variety of machine learning topics.
Some good examples, including real-world blunders.
Gives some practical tools for non-data scientists (including: MonkeyLearn and Orange)
I found Orange to be a lot of fun. It struggled with larger datasets; however, it has a very visual interface that was more user-friendly and offers potential to show some pretty compelling stories.
Example: World Happiness Dataset by:
X-axis: Happiness Score
Y-axis: Economy
Color: Health
Disliked:
Potential to break up content more with relevant imagery -- the content was very dense.
Writers:
iPullRank Team (including Mike King):
Mike King has a few slide decks on the basics of machine learnings and AI
iPullRank has a few data scientists on staff
Links:
http://ipullrank.com/machine-learning-guide/
Tips on Reading:
Read chapters 1-6 and the rest depending upon personal interest.
Review Google PhD ↓
Need to Know: A two-hour presentation from Google's 2017 IO conference that walks through getting 99% accuracy on the MNIST dataset (a famous dataset containing a bunch of handwritten numbers, which the machine must learn to identify the numbers).
Loved:
This talk struck me as very modern, covering the cutting edge.
Found this to be very complementary to Fast.ai, as it covered similar topics (e.g. ReLu, CNNs, RNNs, etc.)
Amazing visuals that help to put everything into context.
Disliked:
The presentation is only a short conference solution and not a comprehensive view of machine learning.
Also, a passive form of learning.
Presenter:
Martin Görner:
Developer Relations, Google (since 2011)
Started Mobipocket, a startup that later became the software part of the Amazon Kindle and its mobile variants
Links:
Part 1 - https://www.youtube.com/watch?v=u4alGiomYP4
Part 2 - https://www.youtube.com/watch?v=fTUwdXUFfI8
Tips on Watching:
Google any concepts you're unfamiliar with.
Take your time with this one; 2 hours of screen time doesn't count all of the Googling and processing time for this one.
Caltech Machine Learning iTunes ↓
Need to Know: If math is your thing, this course does a stellar job of building the mathematic intuition behind many machine learning models. Dr. Abu-Mostafa is a raconteur, includes useful visualizations, relevant real-world examples, and compelling analogies.
Loved:
First and foremost, this is a real Caltech course, meaning it's not a watered-down version and contains fundamental concepts that are vital to understanding the mechanics of machine learning.
On iTunes, audio downloads are available, which can be useful for on-the-go learning.
Dr. Abu-Mostafa is a skilled speaker, making the 27 hours spent listening much easier!
Dr. Abu-Mostafa offers up some strong real-world examples and analogies which makes the content more relatable.
As an example, he asks students: "Why do I give you practice exams and not just give you the final exam?" as an illustration of why a testing set is useful. If he were to just give students the final, they would just memorize the answers (i.e., they would overfit to the data) and not genuinely learn the material. The final is a test to show how much students learn.
The last 1/2 hour of the class is always a Q&A, where students can ask questions. Their questions were useful to understanding the topic more in-depth.
The video and audio quality was strong throughout. There were a few times when I couldn't understand a question in the Q&A, but overall very strong.
This course is designed to build mathematical intuition of what's going on under the hood of specific machine learning models.
Caution: Dr. Abu-Mostafa uses mathematical notation, but it's different from Andrew Ng's (e.g., theta = w).
The final lecture was the most useful, as it pulled a lot of the conceptual puzzle pieces together. The course on neural networks was a close second!
Disliked:
Although it contains mostly evergreen content, being released in 2012, it could use a refresh.
Very passive form of learning, as it wasn't immediately actionable.
Lecturer:
Dr. Yaser S. Abu-Mostafa:
Professor of Electrical Engineering and Computer Science at the California Institute of Technology
Chairman of Machine Learning Consultants LLC
Serves on a number of scientific advisory boards
Has served as a technical consultant on machine learning for several companies (including Citibank).
Multiple articles in Scientific American
Links:
https://work.caltech.edu/telecourse.html
https://itunes.apple.com/us/course/machine-learning/id515364596
Tips on Watching:
Consider listening to the last lesson first, as it pulls together the course overall conceptually. The map of the course, below, was particularly useful to organizing the information taught in the courses.
Image source: http://work.caltech.edu/slides/slides18.pdf
"Pattern Recognition & Machine Learning" by Christopher Bishop ↓
Need to Know: This is a very popular college-level machine learning textbook. I've heard it likened to a bible for machine learning. However, after spending a month trying to tackle the first few chapters, I gave up. It was too much math and pre-requisites to tackle (even with a multitude of Google sessions).
Loved:
The text of choice for many major universities, so if you can make it through this text and understand all of the concepts, you're probably in a very good position.
I appreciated the history aside sections, where Bishop talked about influential people and their career accomplishments in statistics and machine learning.
Despite being a highly mathematically text, the textbook actually has some pretty visually intuitive imagery.
Disliked:
I couldn't make it through the text, which was a bit frustrating. The statistics and mathematical notation (which is probably very benign for a student in this topic) were too much for me.
The sunk cost was pretty high here (~$75).
Writer:
Christopher Bishop:
Laboratory Director at Microsoft Research Cambridge
Professor of Computer Science at the University of Edinburgh
Fellow of Darwin College, Cambridge
PhD in Theoretical Physics from the University of Edinburgh
Links:
https://www.amazon.com/Pattern-Recognition-Learning-Information-Statistics/dp/0387310738/ref=sr_1_2?ie=UTF8&qid=1516839475&sr=8-2&keywords=Pattern+Recognition+%26+Machine+Learning
Tips on Reading:
Don't start your machine learning journey with this book.
Get a friend in statistics to walk you through anything complicated (my plan is to get a mentor in statistics).
Consider taking a (free) online statistics course (Khan Academy and Udacity both have some great content on statistics, calculus, math, and data analysis).
Machine Learning: Hands-on for Developers and Technical Professionals ↓
Need to Know: A fun, non-intimidating end-to-end launching pad/whistle stop for machine learning in action.
Loved:
Talks about practical issues that many other sources didn't really address (e.g. data-cleansing).
Covered the basics of machine learning in a non-intimidating way.
Offers abridged, consolidated versions of the content.
Added fun anecdotes that makes it easier to read.
Overall the writer has a great sense of humor.
Writer talks to the reader as if they're a real human being (i.e., doesn't expect you to go out and do proofs; acknowledges the challenge of certain concepts).
Covers a wide variety of topics.
Because it was well-written, I flew through the book (even though it's about ~300 pages).
Disliked:
N/A
Writer:
Jason Bell:
Technical architect, lecturer, and startup consultant
Data Engineer at MastodonC
Former section editor for Java Developer's Journal
Former writer on IBM DeveloperWorks
Links:
https://www.amazon.com/Machine-Learning-Hands-Developers-Professionals/dp/1118889061
https://www.wiley.com/en-us/Machine+Learning%3A+Hands+On+for+Developers+and+Technical+Professionals-p-9781118889060
Jason's Blog: https://dataissexy.wordpress.com/
Tips on Reading:
Download and explore Weka's interface beforehand.
Give some of the exercises a shot.
Introduction to Machine Learning with Python: A Guide for Data Scientists ↓
Need to Know: This was a was a well-written piece on machine learning, making it a quick read.
Loved:
Quick, smooth read.
Easy-to-follow code examples.
The first few chapters served as a stellar introduction to the basics of machine learning.
Contain subtle jokes that add a bit of fun.
Tip to use the Python package manager Anaconda with Jupyter Notebooks was helpful.
Disliked:
Once again, installation was a challenge.
The "mglearn" utility library threw me for a loop. I had to reread the first few chapters before I figured out it was support for the book.
Although I liked the book, I didn't love it. Overall it just missed the "empowering" mark.
Writers:
Andreas C. Müller:
PhD in Computer Science
Lecturer at the Data Science Institute at Columbia University
Worked at the NYU Center for Data Science on open source and open science
Former Machine Learning Scientist at Amazon
Speaks often on Machine Learning and scikit-learn (a popular machine learning library)
And he makes some pretty incredibly useful graphics, such as this scikit-learn cheat sheet:
Image source: http://peekaboo-vision.blogspot.com/2013/01/machin...
Sarah Guido:
Former senior data scientist at Mashable
Lead data scientist at Bitly
2018 SciPy Conference Data Science track co-chair
Links:
https://www.amazon.com/Introduction-Machine-Learning-Python-Scientists/dp/1449369413/ref=sr_1_7?s=books&ie=UTF8&qid=1516734322&sr=1-7&keywords=python+machine+learning
http://shop.oreilly.com/product/0636920030515.do
Tips on Reading:
Type out code examples.
Beware of the "mglearn" utility library.
Udacity: Machine Learning by Georgia Tech ↓
Need to Know: A mix between an online learning experience and a university machine learning teaching approach. The lecturers are fun, but the course still fell a bit short in terms of active learning.
Loved:
This class is offered as CS7641 at Georgia Tech, where it is a part of the Online Masters Degree. Although taking this course here will not earn credit towards the OMS degree, it's still a non-watered-down college teaching philosophy approach.
Covers a wide variety of topics, many of which reminded me of the Caltech course (including: VC Dimension versus Bayesian, Occam's razor, etc.)
Discusses Markov Decision Chains, which is something that didn't really come up in many other introductory machine learning course, but they are referenced within Google patents.
The lecturers have a great dynamic, are wicked smart, and displayed a great sense of (nerd) humor, which make the topics less intimidating.
The course has quizzes, which give the course a slight amount of interaction.
Disliked:
Some videos were very long, which made the content a bit harder to digest.
The course overall was very time consuming.
Despite the quizzes, the course was a very passive form of learning with no assignments and little coding.
Many videos started with a bunch of content already written out. Having the content written out was probably a big time-saver, but it was also a bit jarring for a viewer to see so much information all at once, while also trying to listen.
It's vital to pay very close attention to notation, which compounds in complexity quickly.
Tablet version didn't function flawlessly: some was missing content (which I had to mark down and review on a desktop), the app would crash randomly on the tablet, and sometimes the audio wouldn't start.
There were no subtitles available on tablet, which I found not only to be a major accessibility blunder, but also made it harder for me to process (since I'm not an audio learner).
Lecturer:
Michael Littman:
Professor of Computer Science at Brown University.
Was granted a patent for one of the earliest systems for Cross-language information retrieval
Perhaps the most interesting man in the world:
Been in two TEDx talks
How I Learned to Stop Worrying and Be Realistic About AI
A Cooperative Path to Artificial Intelligence
During his time at Duke, he worked on an automated crossword solver (PROVERB)
Has a Family Quartet
He has appeared in a TurboTax commercial
Charles Isbell:
Professor and Executive Associate Dean at School of Interactive Computing at Georgia Tech
Focus on statistical machine learning and "interactive" artificial intelligence.
Links:
https://www.udacity.com/course/machine-learning--ud262
Tips on Watching:
Pick specific topics of interest and focusing on those lessons.
Andrew Ng's Stanford's Machine Learning iTunes ↓
Need to Know: A non-watered-down Stanford course. It's outdated (filmed in 2008), video/audio are a bit poor, and most links online now point towards the Coursera course. Although the idea of watching a Stanford course was energizing for the first few courses, it became dreadfully boring. I made it to course six before calling it.
Loved:
Designed for students, so you know you're not missing out on anything.
This course provides a deeper study into the mathematical and theoretical foundation behind machine learning to the point that the students could create their own machine learning algorithms. This isn't necessarily very practical for the everyday machine learning user.
Has some powerful real-world examples (although they're outdated).
There is something about the kinesthetic nature of watching someone write information out. The blackboard writing helped me to process certain ideas.
Disliked:
Video and audio quality were pain to watch.
Many questions asked by students were hard to hear.
On-screen visuals range from hard to impossible to see.
Found myself counting minutes.
Dr. Ng mentions TA classes, supplementary learning, but these are not available online.
Sometimes the video showed students, which I felt was invasive.
Lecturer:
Andrew Ng (see above)
Links:
https://itunes.apple.com/us/course/machine-learning/id495053006
https://www.youtube.com/watch?v=UzxYlbK2c7E
Tips on Watching:
Only watch if you're looking to gain a deeper understanding of the math presented in the Coursera course.
Skip the first half of the first lecture, since it's mostly class logistics.
Additional Resources
Fast.ai (part 2) - free access to materials, cost for AWS EC2 instance
Deeplearning.ai - $50/month
Udacity Machine Learning Engineer Nanodegree - $1K
https://machinelearningmastery.com/
Motivations and inspiration
If you're wondering why I spent a year doing this, then I'm with you. I'm genuinely not sure why I set my sights on this project, much less why I followed through with it. I saw Mike King give a session on Machine Learning. I was caught off guard, since I knew nothing on the topic. It gave me a pesky, insatiable curiosity itch. It started with one course and then spiraled out of control. Eventually it transformed into an idea: a review guide on the most affordable and popular machine learning resources on the web (through the lens of a complete beginner). Hopefully you found it useful, or at least somewhat interesting. Be sure to share your thoughts or questions in the comments!
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes